Pacote ggplot2: um curso introdutório
Construído baseado nos pacotes tidyverse e ggplot2 do R.
2 horas por dia, por 2 dias
PRIMEIRA PARTE
Primeiramente, todo e qualquer resultado estatístico obtido em qualquer software estatístico deve ser bem compreendido antes de sua apresentação. As saídas gráficas desses resultados compreendem uma importante ferramenta resumidora do comportamento dos dados amostrais observados e até mesmo de poulações inteiras, envolvendo diversos fenômenos que podem ser compreendidos usando essas ferramentas estatísticas. As saídas gráficas do R e do rstudio não são diferentes.
Aqui nessas notas nós poderíamos simplesmente selecionar alguns pacotes disponíveis no rstudio que fornecem uma guia interativa para a produção de gráficos no pacote ggplot2 e apresentá-los, tais como os pacotes esquisse e ggplotgui. Mas esse não é o nosso objetivo.
Portanto, nós iremos apresentar o pacote ggplot2 de forma lenta e gradativa, apresentando o seu diferencial com relação a outros pacotes e também outras funções de saídas gráficas do R e do rstudio, além de mostrar o passo a passo de como se dá a construção de saídas gráficas desse pacote no rstudio, entendo suas funções internas e seus argumentos.
Antes de iniciarmos a apresentação desse pacote, apresentamos um conjunto de funções que verificrá se os pacotes aqui necessários estão instalados no rstudio e, em seguida, fará o carregamento desses pacotes no mesmo.
packages <- c("dplyr","tidyverse","lattice", "rgdal", "rgeos", "maptools", "plyr", "sf", "covid19br", "RColorBrewer")
# instala os pacotes que não estão instalados
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {
install.packages(packages[!installed_packages])
}
# carrega os pacotes
invisible(lapply(packages, library, character.only = TRUE))
Introdução
Não é incomum em qualquer análise estatítica de um conjunto de dados, nos depararmos com a necessidade da utilização de recursos gráficos para representar e conhecer, de forma resumida, o comportamento das variáveis de interesse do mesmo. O R possui algumas funções implementadas em sua base (não é necessário a instalação de pacotes), tais como as funções plot, hist, barplot, boxplot, pie, entre outras e também, alguns pacotes de recursos gráficos, como o lattice.
Vamos agora exemplificar como construir um histograma e um gráfico de barras utilizando as respectivas funções disponíveis na base do R e também o pacote mencionado utilizando o conjunto de dados mtcars disponível no R. Os dados foram coletados da revista “Motor Trend US (1974)” e diz respeito ao consumo de combustível e também outros 10 aspectos de design e desempenho de 32 modelos de automóveis compreendidos entre os anos de 1973 e 1974.
mtcars <- within(mtcars, {
vs <- factor(vs, labels = c("V", "S"))
am <- factor(am, labels = c("automatica", "manual"))
cyl <- ordered(cyl)
gear <- ordered(gear)
carb <- ordered(carb)
})
summary(mtcars)
## mpg cyl disp hp drat
## Min. :10.40 4:11 Min. : 71.1 Min. : 52.0 Min. :2.760
## 1st Qu.:15.43 6: 7 1st Qu.:120.8 1st Qu.: 96.5 1st Qu.:3.080
## Median :19.20 8:14 Median :196.3 Median :123.0 Median :3.695
## Mean :20.09 Mean :230.7 Mean :146.7 Mean :3.597
## 3rd Qu.:22.80 3rd Qu.:326.0 3rd Qu.:180.0 3rd Qu.:3.920
## Max. :33.90 Max. :472.0 Max. :335.0 Max. :4.930
## wt qsec vs am gear carb
## Min. :1.513 Min. :14.50 V:18 automatica:19 3:15 1: 7
## 1st Qu.:2.581 1st Qu.:16.89 S:14 manual :13 4:12 2:10
## Median :3.325 Median :17.71 5: 5 3: 3
## Mean :3.217 Mean :17.85 4:10
## 3rd Qu.:3.610 3rd Qu.:18.90 6: 1
## Max. :5.424 Max. :22.90 8: 1
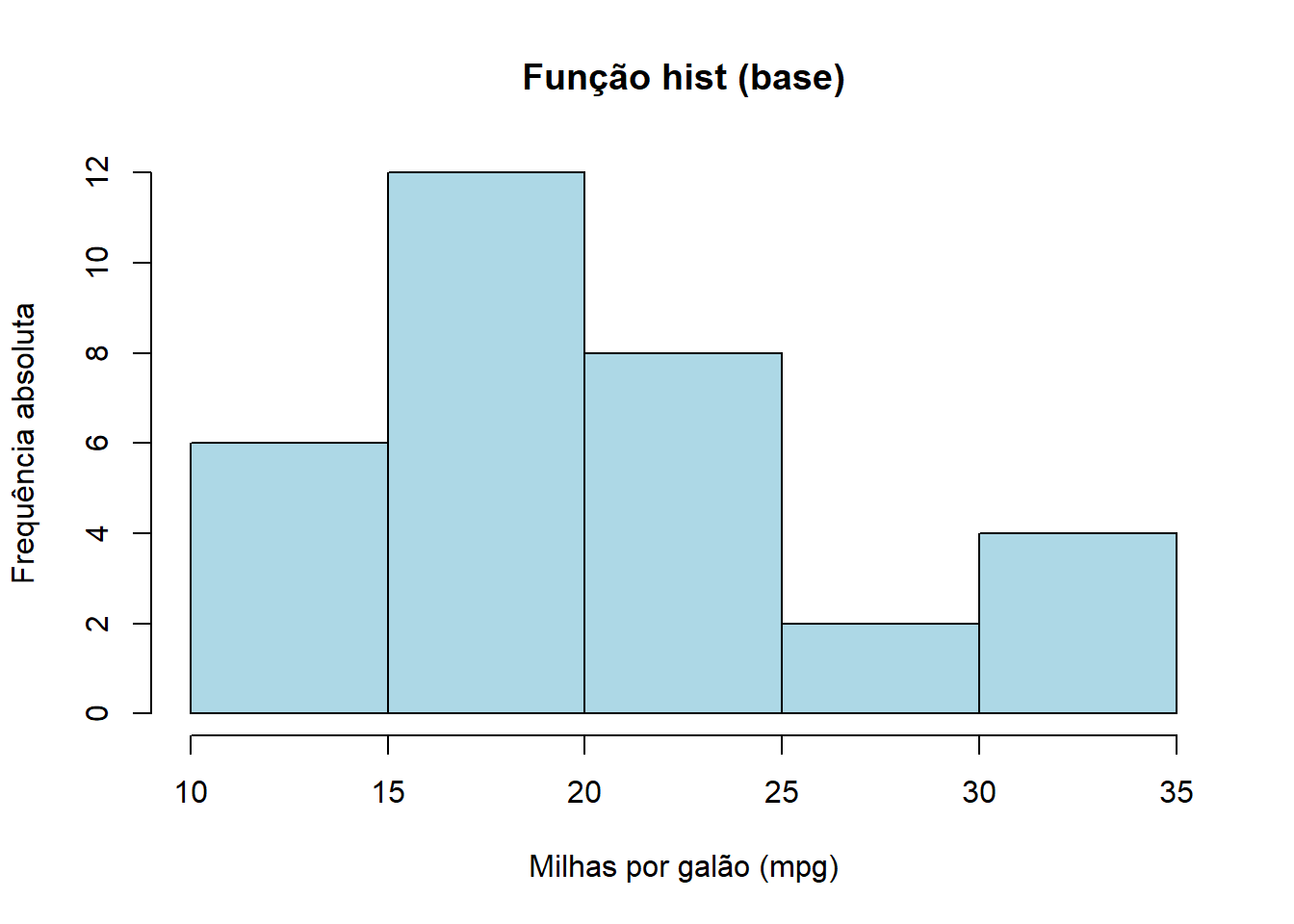
Vamos escolher a variável mpg (milhas percorrida por galão de combustível), que é de natureza numérica e contínua para gerarmos um histograma (frequência absoluta) utilizando a função hist da base do R e também utilizando o pacote lattice.
hist(mtcars$mpg, col = "lightblue", main = "Função hist (base)",
xlab = "Milhas por galão (mpg)", ylab = "Frequência absoluta")
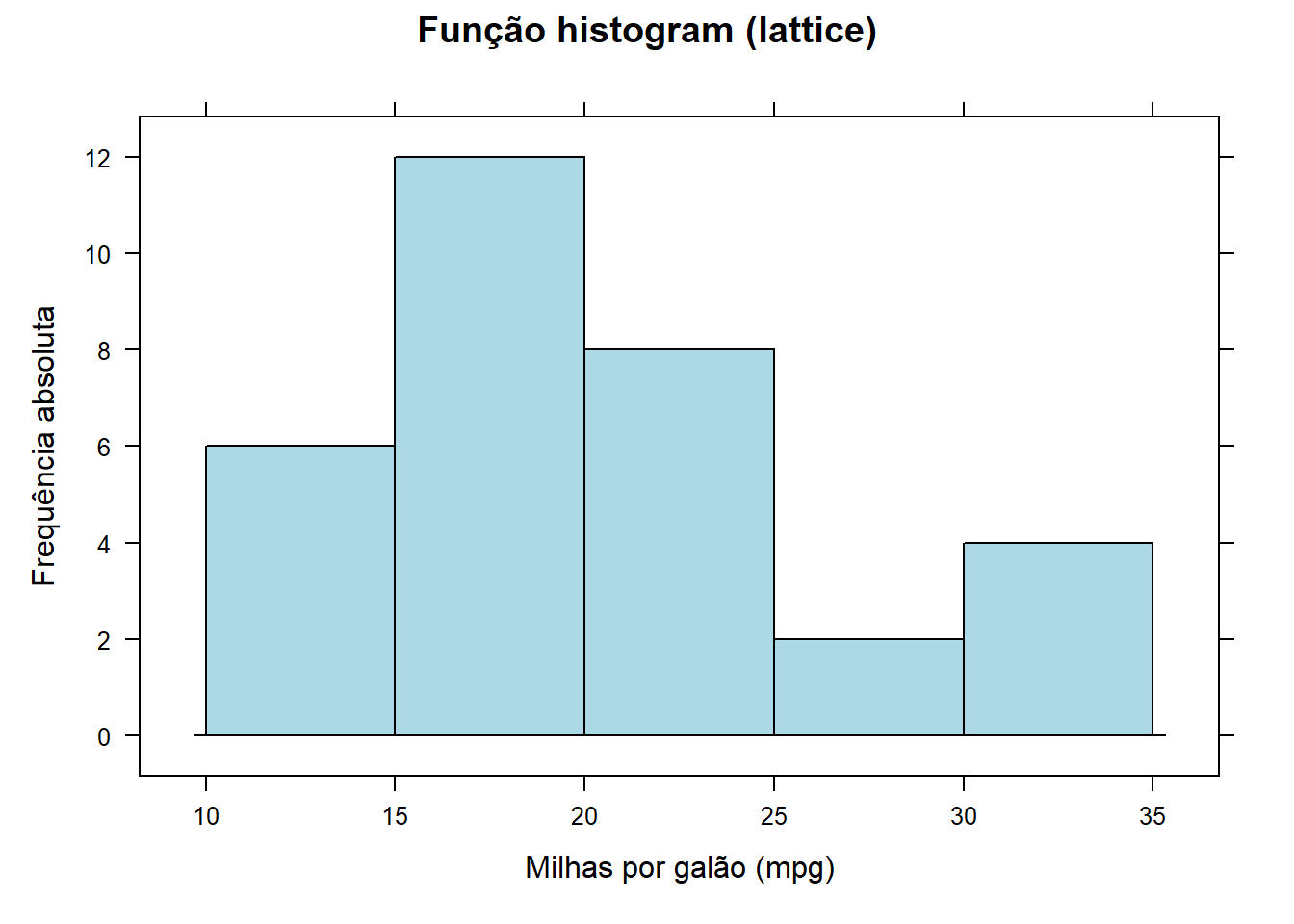
library(lattice)
histogram(~mpg,data=mtcars,
type ="count",
xlab ="Milhas por galão (mpg)",
ylab = "Frequência absoluta",
main ="Função histogram (lattice)",
col = "lightblue",
breaks = 5)
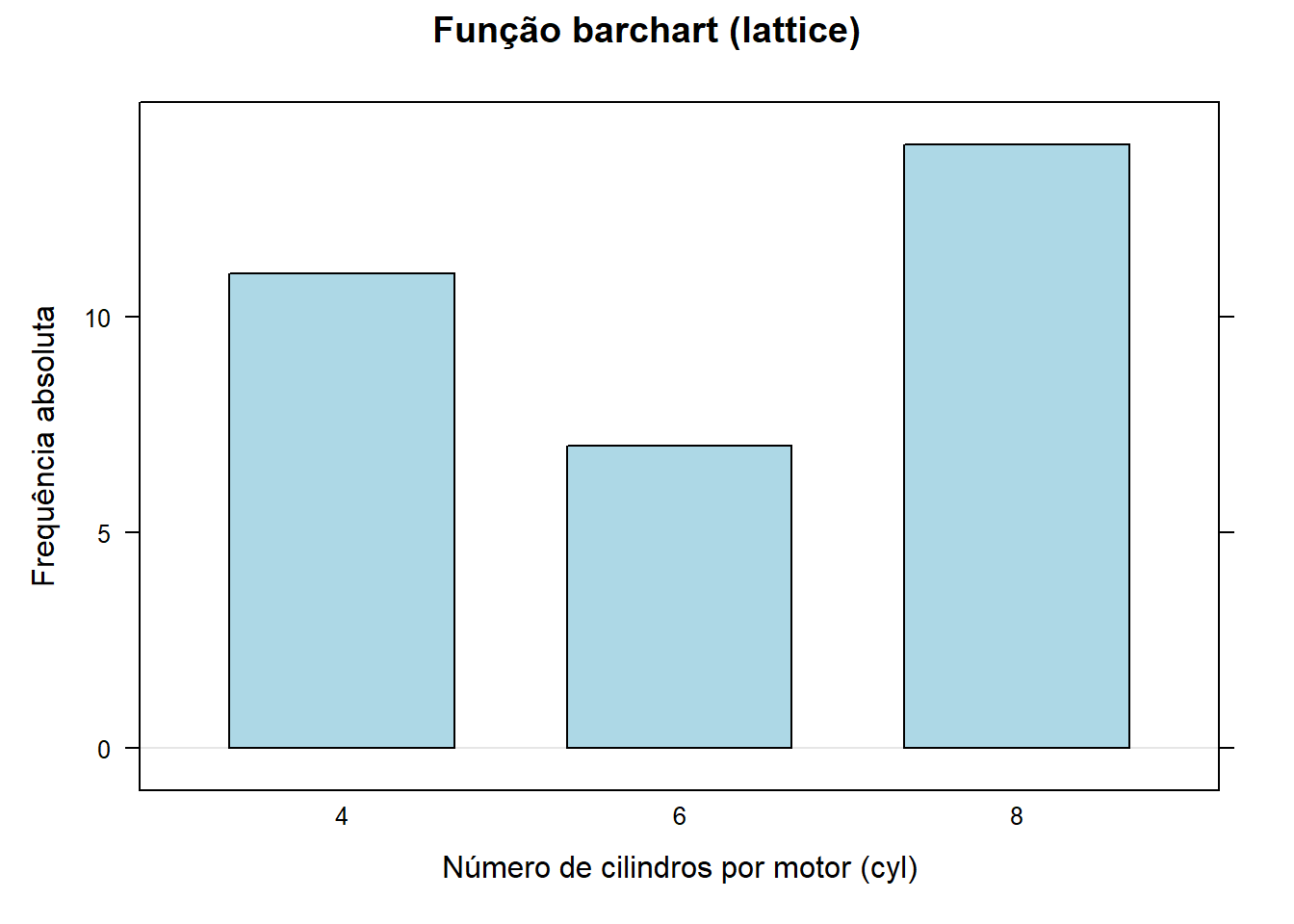
Vamos agora utilizar a variável cyl (número de cilindros) para construírmos um gráfico de barras (frequência absoluta) utilizando a função barplot da base do R e também o pacote lattice.
tab <- table(mtcars$cyl)
tab
##
## 4 6 8
## 11 7 14
barplot(tab, col = "lightblue", main = "Função barplot (base)", xlab = "Número de cilindros por motor (cyl)", ylab = "Frequência absoluta")

library(lattice)
tabela <- xtabs(~cyl, data = mtcars)
tabela
## cyl
## 4 6 8
## 11 7 14
barchart(tabela,
horizontal = FALSE,
main = "Função barchart (lattice)",
xlab = "Número de cilindros por motor (cyl)",
ylab = "Frequência absoluta",
col = "lightblue")
Bastam esses dois exemplos para percebermos algumas situações: para cada tipo de gráfico escolhido de acordo com a natureza da variável, o conjunto de linhas de comandos necessários para gerá-los no R é único e particular; é necessário também a utilização de funções adicionais (table) e funções específicas do pacote lattice (xtabs) para a construção dos gráficos de barras. Essas situações forçam o usuário a ter conhecimento de cada uma dessas funções particulares e também seus argumentos.
Essas justificativas são suficientes para pensarmos em algum pacote que torne mais fácil ao usuário a construção de gráficos no R. Esse pacote existe e é o pacote ggplot2, que é o objetivo desse curso. Vamos conhecer um pouco mais desse pacote e observar suas vantagens.
O pacote ggplot2
No ano de 2005, o estatístico, cientista computacional e professor adjunto norte-americano Leland Wilkinson, da University of Illinois (Chicago), publicou o livro “The grammar of Graphics”, que trata de uma fonte de princípios fundamentais para a construção de gráficos estatísticos. O autor defende a ideia que um gráfico é uma mapeamento dos dados em atributos estéticos (posição, cor, forma, tamanho, etc) de formas geométricas (pontos, linhas, barras, caixas, etc).
Em sua tese de doutorado (2008), Hadley Wickham adotou a filosofia defendida por Leland para responder a pergunta “O que é um gráfico estatístico?”, criando, então, o pacote ggplot2.
Hadley então, escreveu o livro “A Layered Grammar of Graphics”, onde incrementou às ideias de Leland a visão de que os elementos de um gráfico (dados, sistema de coordenadas, rótulos, anotações, entre outros) são as suas camadas e que a construção de um gráfico se dá pela sobreposição dessas camadas. Essa é a essência do pacote ggplot2: construir um gráfico camada por camada.
Aliado a essa filosofia bem fundamentada, esse pacote ainda traz algumas vantagens: geralmente os gráficos construídos são mais bonitos e apresentáveis, são de fácil personalização e apresentam uma estrutura (sintaxe) padronizada.
A gramática em camadas de gráficos
Basicamente podemos descrever individualmente qualquer gráfico estatístico como uma combinação de um conjunto de dados, um geom, um conjunto de mapeamentos, um stat, um ajuste de posição, um sistema de coordenadas e um esquema de facetas.
Abaixo apresentamos os seis elementos que envolvem a construção de gráficos estatísticos no ggplot2. Os elementos marcados com * são essenciais e obrigatórios. Os termos em negrito, como em aes, representam as funções a serem utilizadas no ggplot2 para a construção dos gráficos estatísticos.
| Elementos | Exemplos |
|---|---|
| aestética$^*$ | cor, formato |
| geometrias$^*$ | barra, ponto |
| estatísticas (modelos) | mediana, máximo |
| facetas | facetas |
| coordenadas | polar, cartesiana |
| themas | eixos, títulos |
Vamos agora realizar essa construção passo a passo no R. Os dados devem ser um data.frame. Essa condição é obrigatória para o uso do ggplot2. Primeiramente vamos instalar e carregar o pacote ggplot2. Depois, vamos colocar o conjunto de dados mtcars, disponível no R, em data.frame. Feito isso, nós estamos em condições de iniciar a construção de gráficos no ggplot2.
A primeira camada (layer) necessária para a criação de gráficos no ggplot2 é dada pelo comando ggplot(dados). Neste comando, estamos criando a área onde o gráfico será construído e, ainda, informando ao ggplot2 qual o conjunto de dados que contém as variáveis de interesse.
ggplot(mtcars)

Nós notamos que é criado uma área (em cinza) onde será construído o gráfico. Essa área ainda não contém nenhum formato geométrico (geom_tipo) como, por exemplo, pontos, barras, caixas, etc. Falta também a informação da estética do gráfico desejado juntamente com as variáveis de interesse aes(x,y,cores). Esse é o próximo passo. Note também que a cada acréscimo de camada utilzamos o sinal +.
A variável mpg já foi apresentada e utilizada nos gráficos anteriores. A variável disp significa quantas cilindradas o motor do veículo possui. Note que ainda não escolhemos a cor dos pontos do gráfico nem rotulamos seus eixos. Nosso gráfico ainda está incompleto.
ggplot(mtcars) +
geom_point(mapping = aes(x= disp, y=mpg))
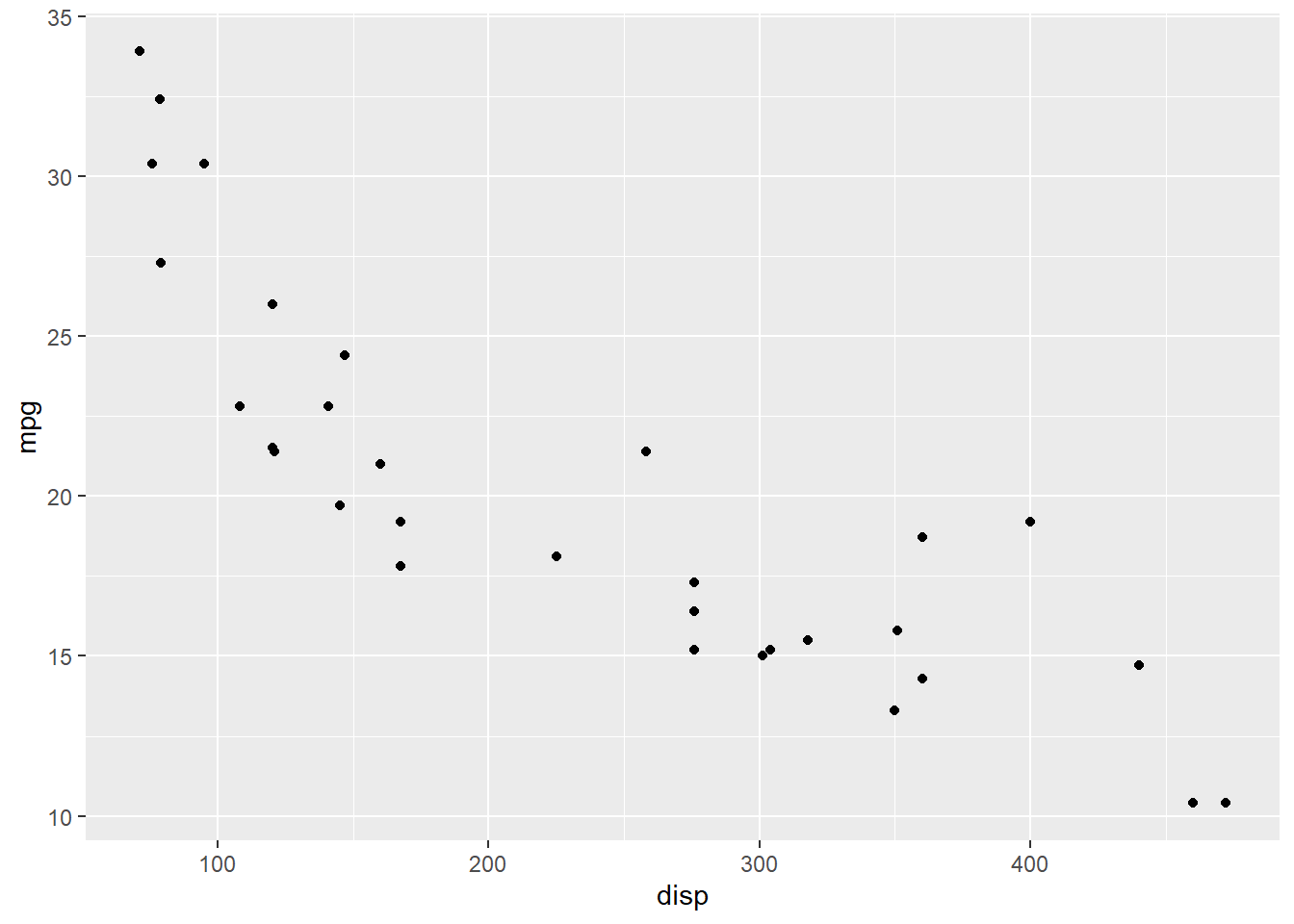
No pacote gplot2 nós também temos a liberdade de escolher a escala de cores que iram compor o nosso gráfico. Para isso temos três argumentos: color e colour, que se diferem devido a lingua ingleza e fill. Os dois primeiros são utilizados em entes geométricos que não possuem área, tais como pontos e linhas, sendo necessário utilizar apenas um deles e a escolha fica a critério do usuário. Já o comando fill é utilizado naquele ente geométrico que possui área, sendo responsável pelo preenchimento dessa área com a cor desejada. Ambos devem ser utilizados junto ao comando geom_tipo.
Vamos agora ver dois exemplos de utilização desses argumentos.
ggplot(mtcars) +
geom_point(mapping = aes(x= disp, y=mpg, color=as.factor(am))) +
labs(x="Cilindradas", y="Milhas/galão")
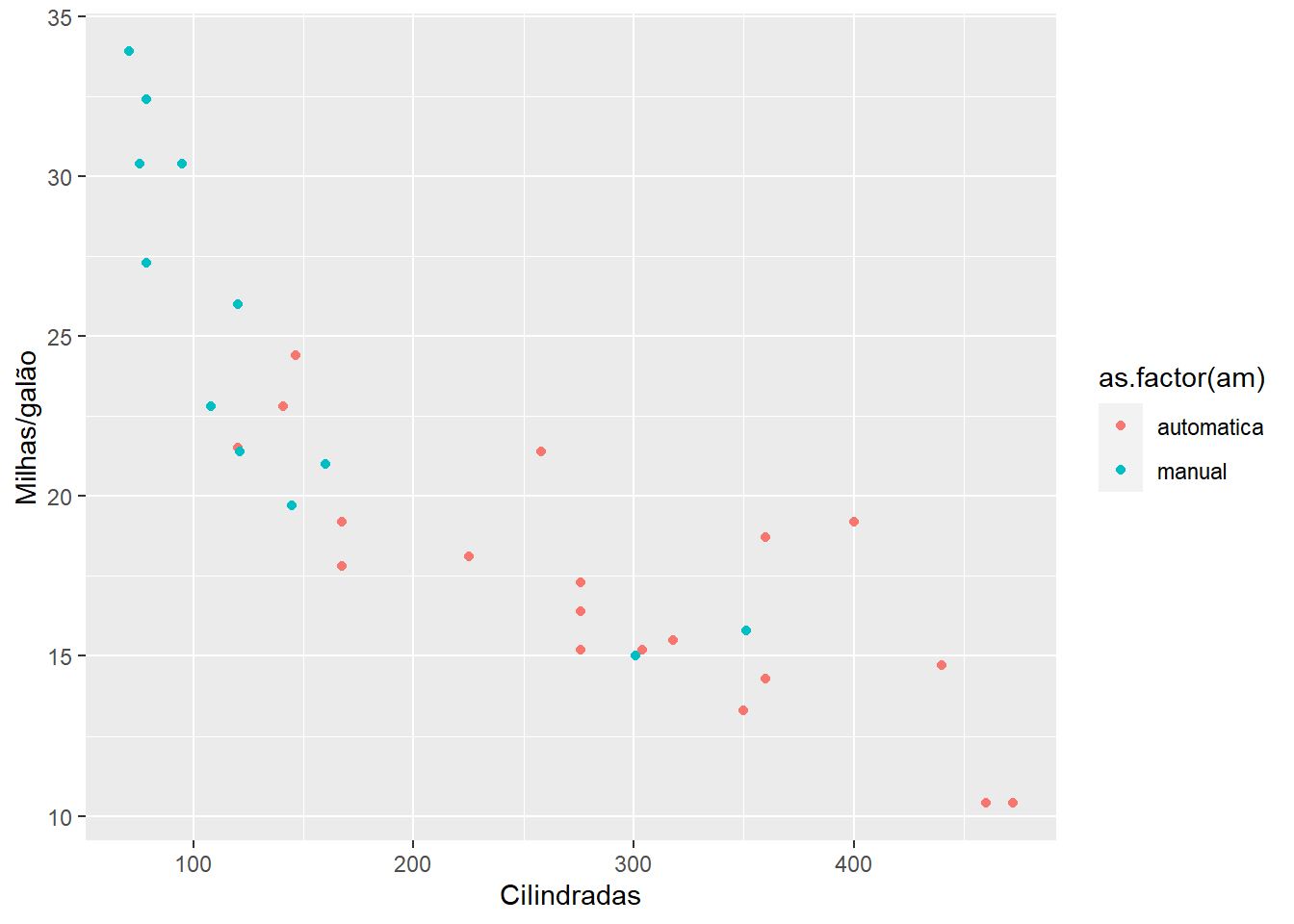
ggplot(mtcars) +
geom_point(mapping = aes(x= disp, y=mpg), color=c("red")) +
labs(x="Cilindradas", y="Milhas/galão")
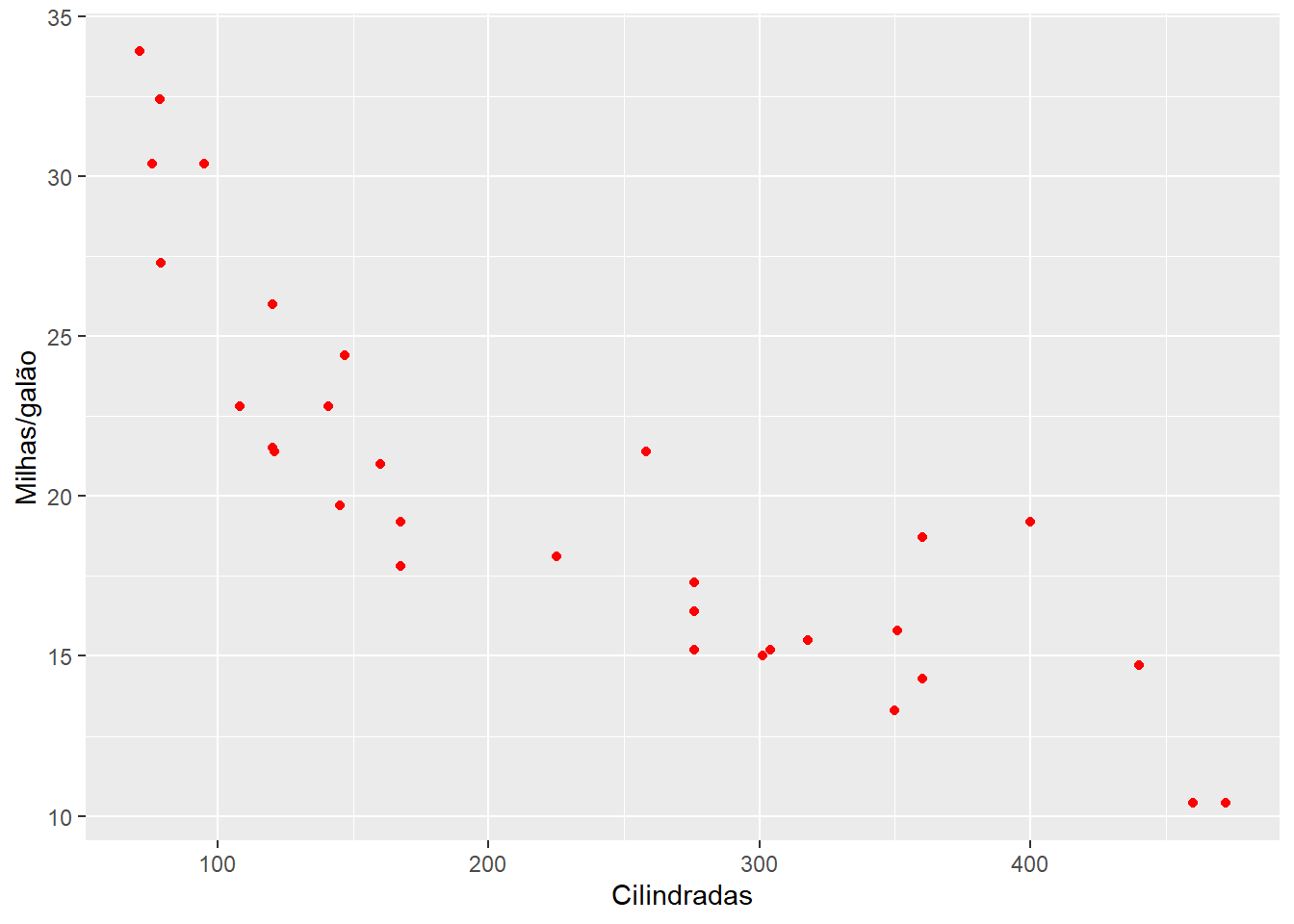
Nós notamos que se utilizarmos o argumento para a escolha das cores dentro da função aes, este deve estar relaciondo a alguma variável específica. No nosso exemplo, é o tipo de transmissão do carro a variável em questão. Caso esse argumento seja utilizado fora da função aes, nós temos a liberdade de escolha das cores, pois ela não estão relacionadas as variáveis em questão.
Tente utilizar o argumento de cores relacionado a variávies fora da função aes e verá que o R retornará uma mensagem de erro, dizendo que não reconhece a variável.
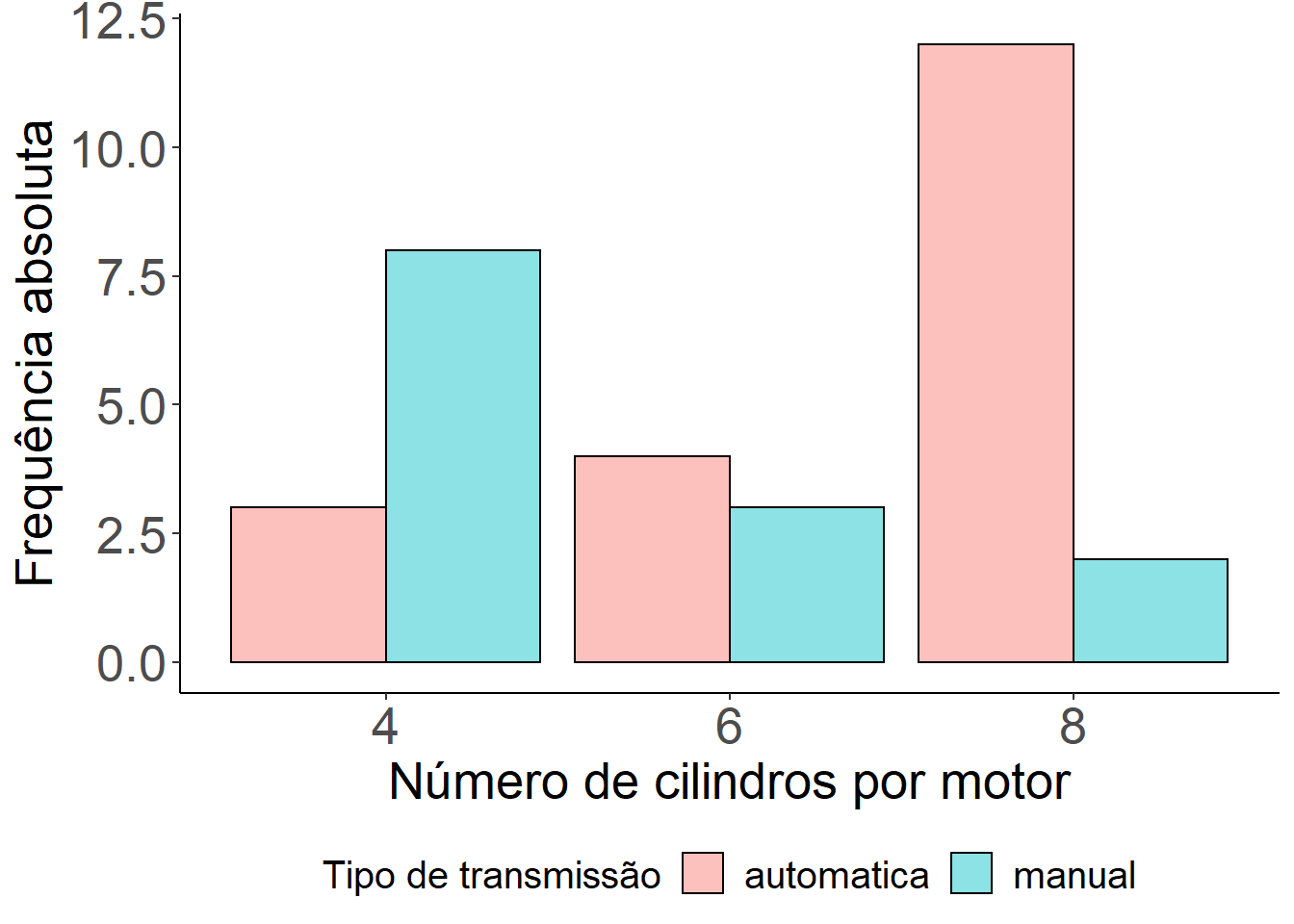
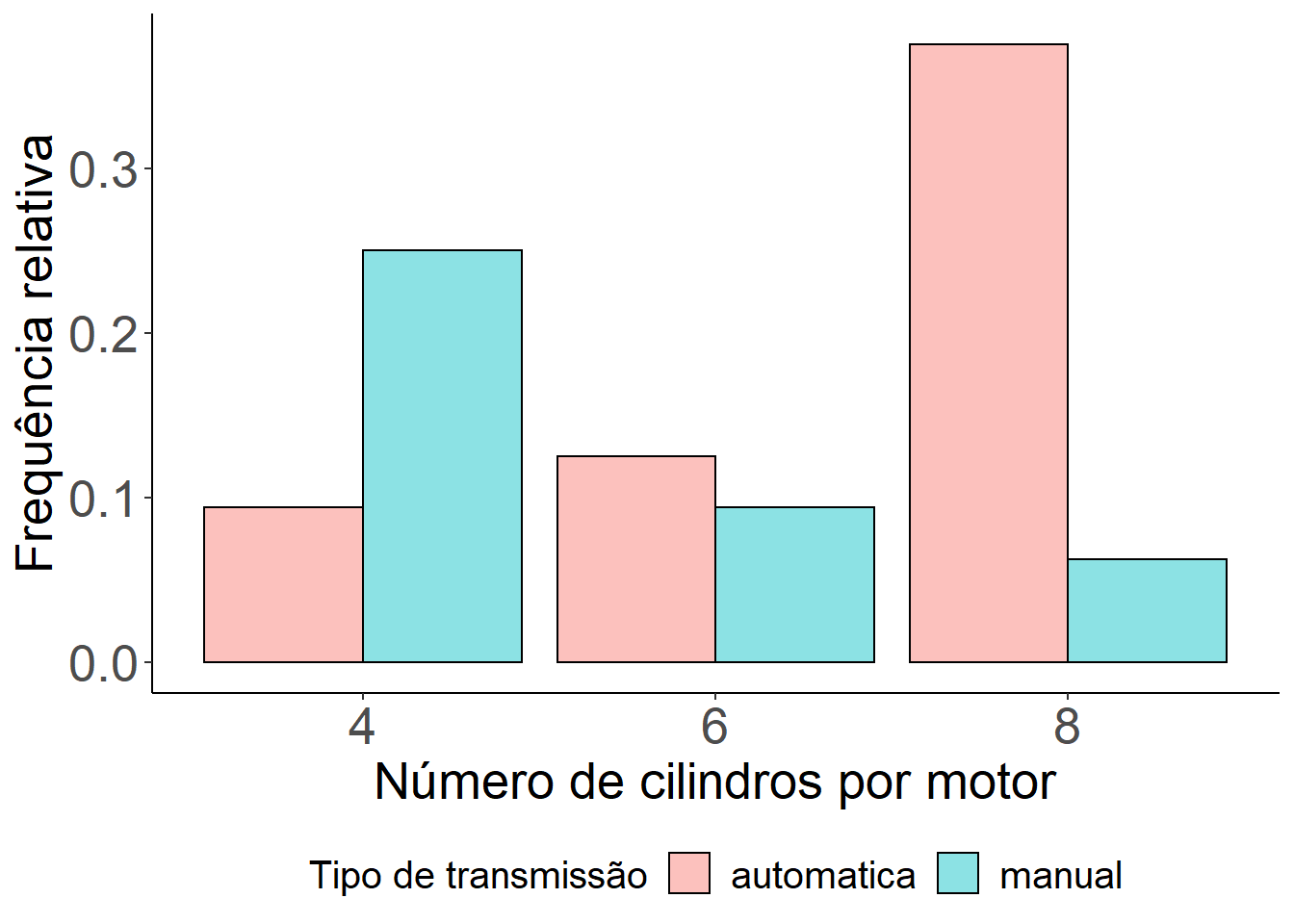
Vamos agora apresentar um gráfico de barras onde o interesse é apresentar as frequências absolutas, relativas e percentual da quantidade de cilindros que o motor do carro possui (cyl) separados por tipo de transmissão (am) .
ggplot(mtcars, aes(x = as.factor(cyl))) +
geom_bar(aes(y = (..count..), fill=as.factor(am)),
position = "dodge", colour="black", alpha=0.45)+
labs(x = "Número de cilindros por motor", y = "Frequência absoluta", fill = "Tipo de transmissão") +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
ggplot(mtcars, aes(x = as.factor(cyl))) +
geom_bar(aes(y = (..count..)/sum(..count..), fill=as.factor(am)),
position = "dodge", colour="black", alpha=0.45)+
labs(x = "Número de cilindros por motor", y = "Frequência relativa", fill = "Tipo de transmissão") +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
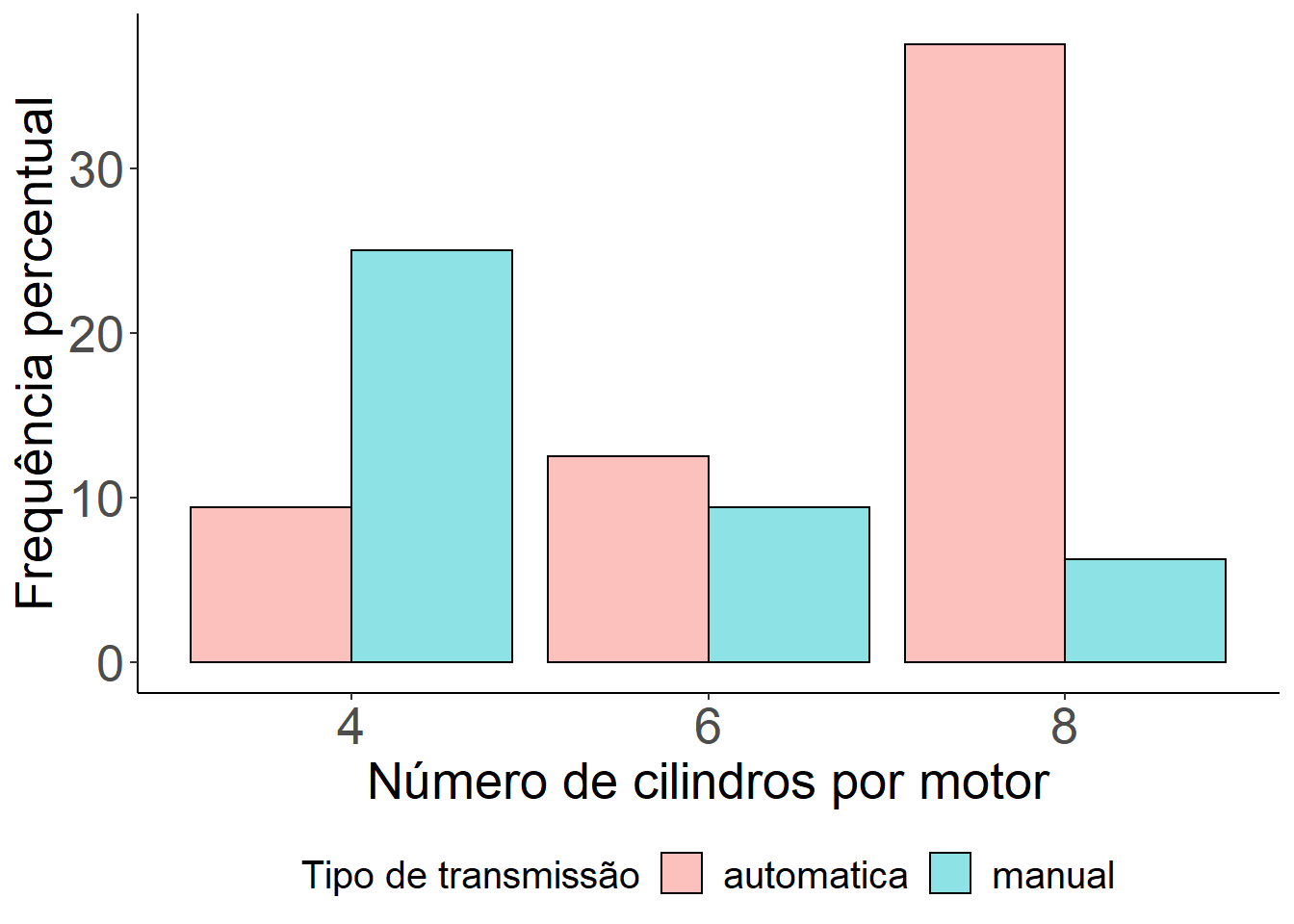
ggplot(mtcars, aes(x = as.factor(cyl))) +
geom_bar(aes(y = (..count..)/sum(..count..)*100, fill=as.factor(am)),
position = "dodge", colour="black", alpha=0.45)+
labs(x = "Número de cilindros por motor", y = "Frequência percentual", fill = "Tipo de transmissão") +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
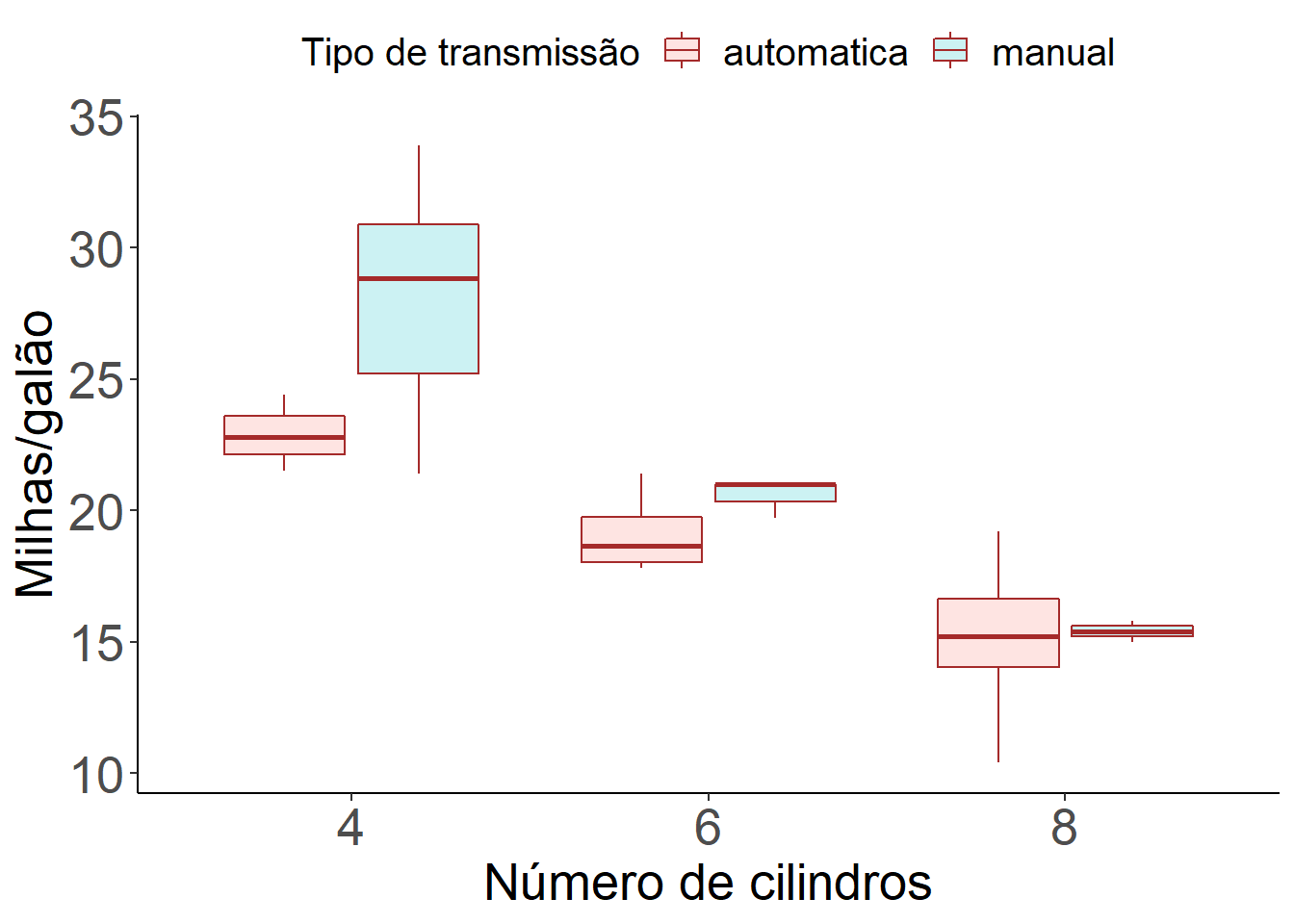
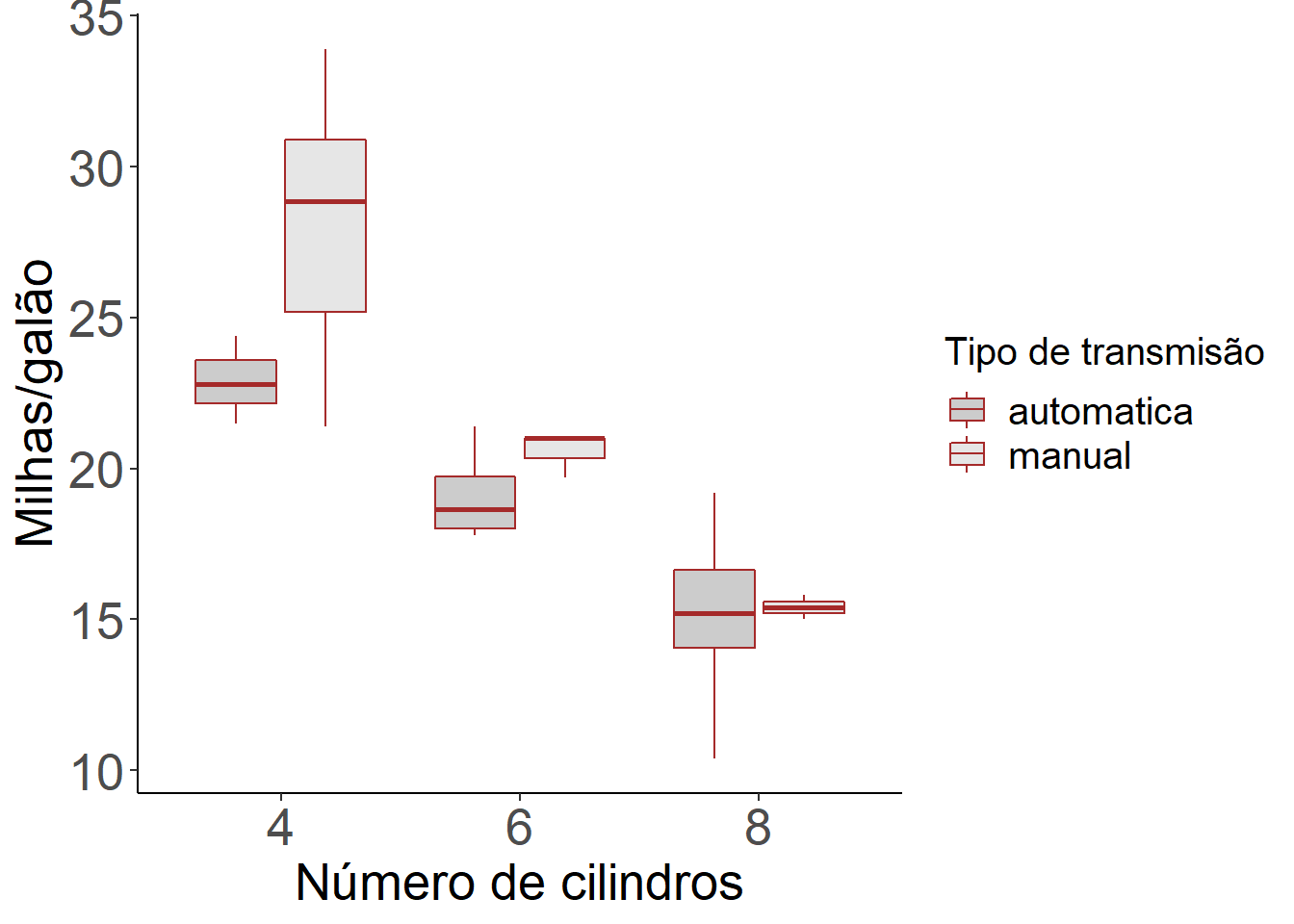
Vamos agora construir um gráfico do tipo boxplot utilizando o pacote ggplot2.
ggplot(mtcars) +
geom_boxplot(aes(x = as.factor(cyl), y = mpg, fill=as.factor(am)), colour="brown", alpha=0.2) +
labs(x = "Número de cilindros", y = "Milhas/galão", fill = "Tipo de transmissão") +
theme_bw() +
theme(legend.position="top",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
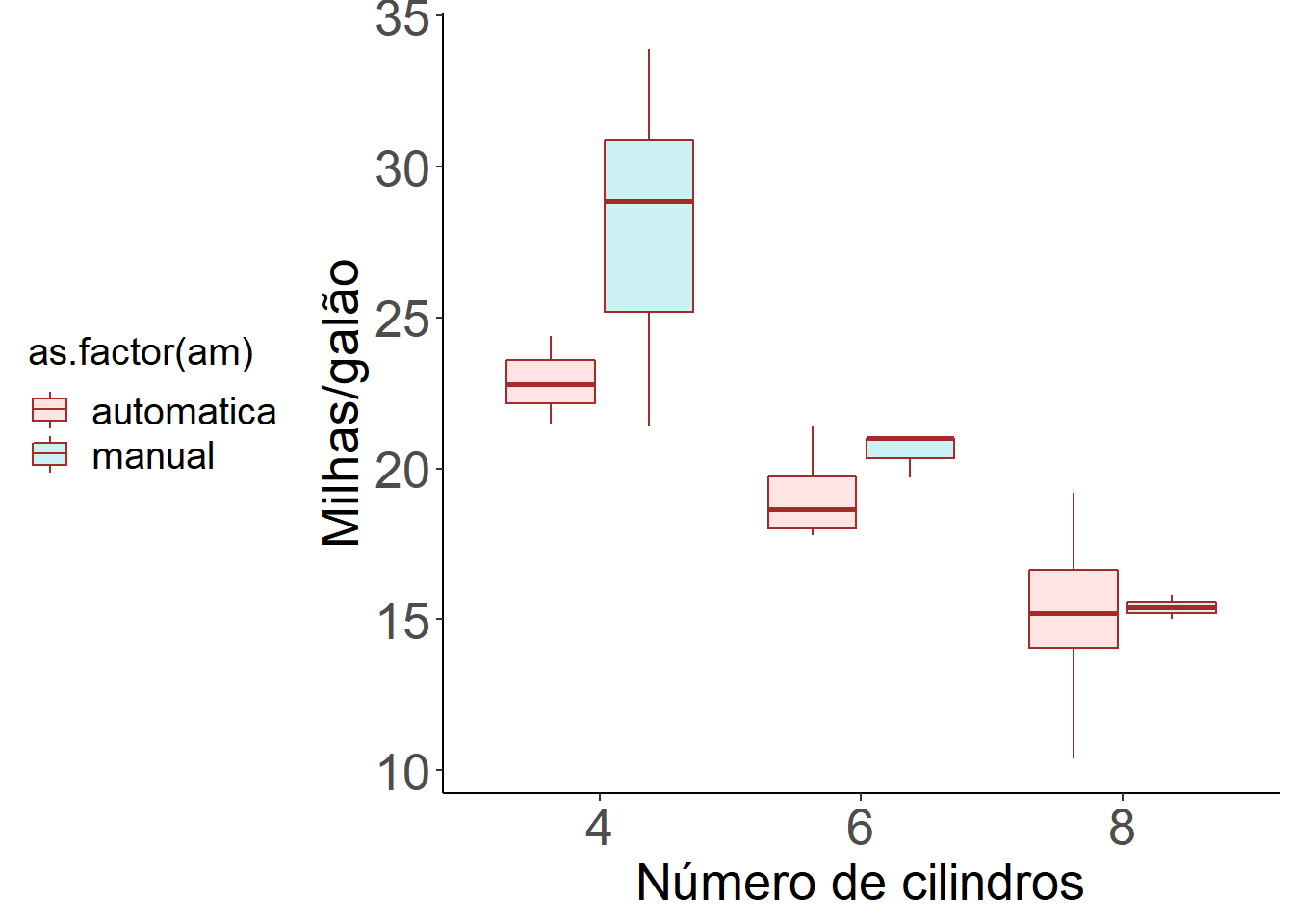
ggplot(mtcars) +
geom_boxplot(aes(x = as.factor(cyl), y = mpg, fill=as.factor(am)), colour="brown", alpha=0.2) +
labs(x = "Número de cilindros", y = "Milhas/galão", fill = "Tipo de transmissão") +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())

ggplot(mtcars) +
geom_boxplot(aes(x = as.factor(cyl), y = mpg, fill=as.factor(am)), colour="brown", alpha=0.2) +
labs(x = "Número de cilindros", y = "Milhas/galão") +
theme_bw() +
theme(legend.position="left",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
cor <- gray(0:2 / 2)
ggplot(mtcars) +
geom_boxplot(aes(x = as.factor(cyl), y = mpg, fill=as.factor(am)), colour="brown",
alpha=0.2) +
labs(x = "Número de cilindros", y = "Milhas/galão", fill = "Tipo de transmisão") +
theme_bw() +
theme(legend.position="right",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank()) +
scale_fill_manual(values=cor)
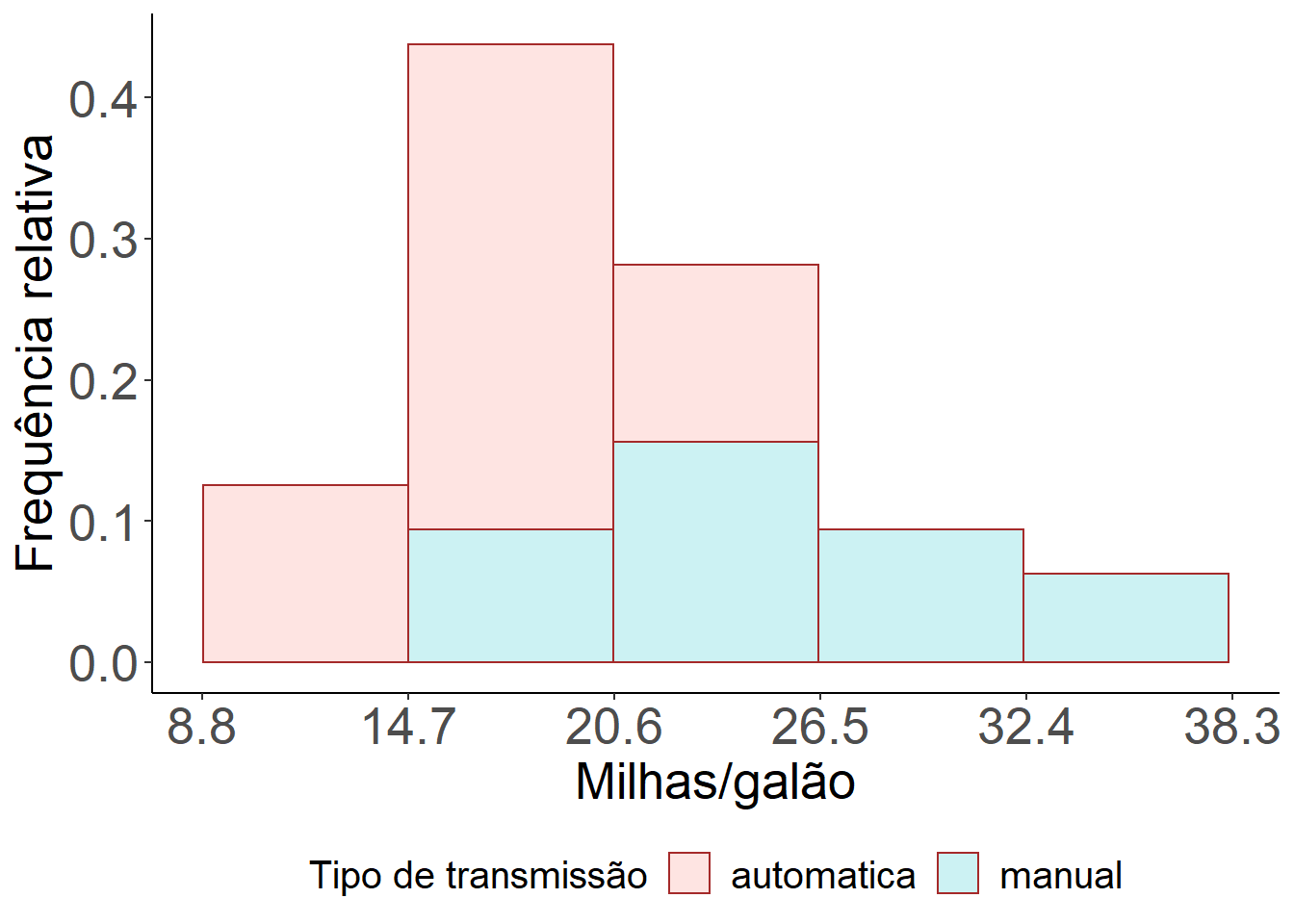
Vamos agora construir alguns histogramas com frequências absolutas, relativas e percentuais, nessa ordem. Note que o comando bins define o número de classes a ser escolhido. Neste exemplo escolhemos arbitrariamente bins igual a 5, mas o usuário pode fazer os cálculos manualmente e utilizá-lo. Nós também definimos a escala dos eixos x e y manualmente, através dos comandos scale_x_continuous e scale_y_continuous.
ggplot(mtcars) +
geom_histogram(aes(x = mpg, y = (..count..)/sum(..count..), fill=as.factor(am)),
bins=5, colour="brown", alpha=0.2)+
labs(x = "Milhas/galão", y = "Frequência relativa", fill = "Tipo de transmissão") +
scale_y_continuous(breaks = c(seq(0,1,0.1)))+
scale_x_continuous(breaks = c(seq(8.8,38.3,5.9))) +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
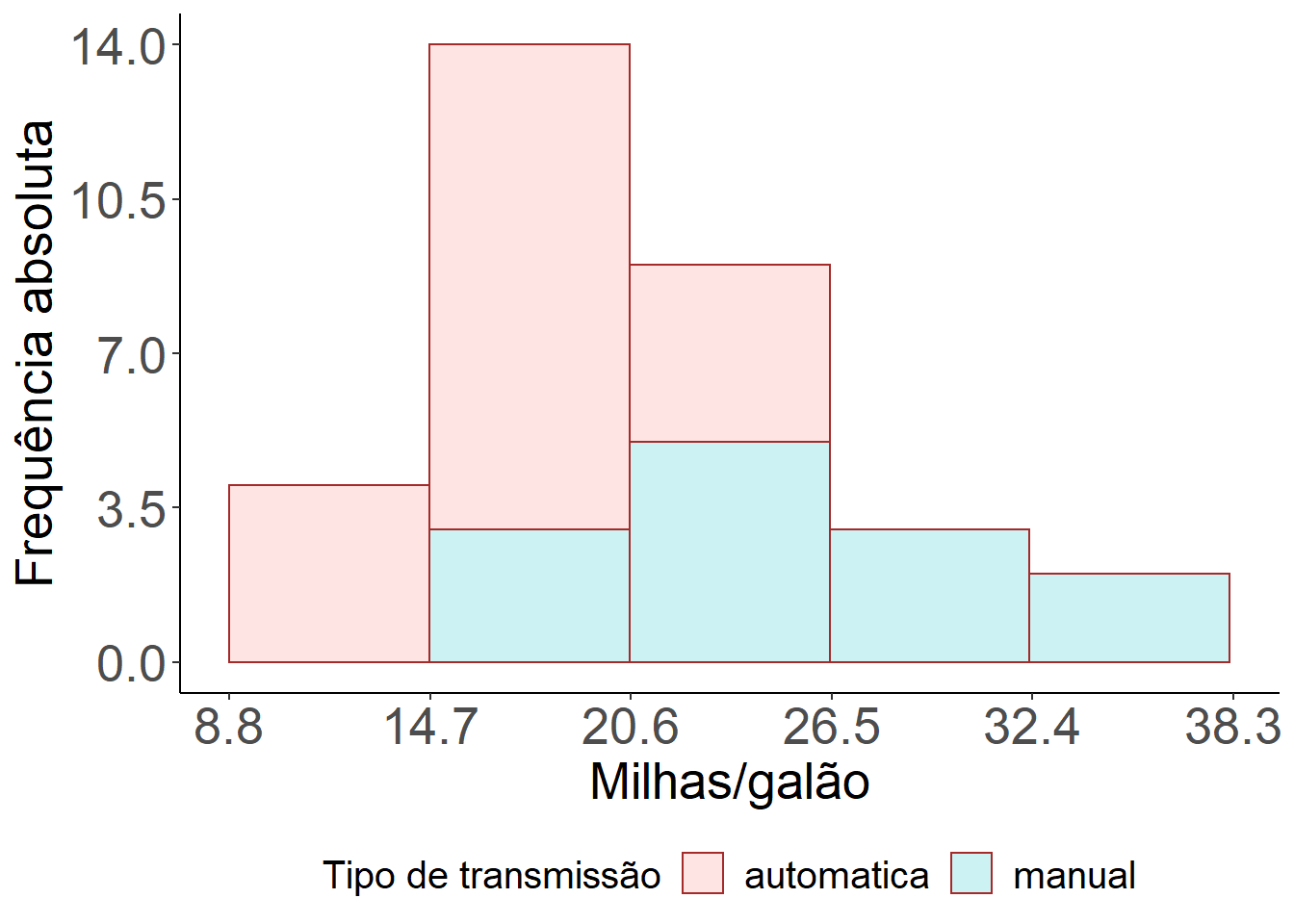
ggplot(mtcars) +
geom_histogram(aes(x = mpg, y = (..count..), fill=as.factor(am)), bins=5,
colour="brown", alpha=0.2)+
labs(x = "Milhas/galão", y = "Frequência absoluta", fill = "Tipo de transmissão") +
scale_y_continuous(breaks = c(seq(0,15,3.5))) +
scale_x_continuous(breaks = c(seq(8.8,38.3,5.9))) +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
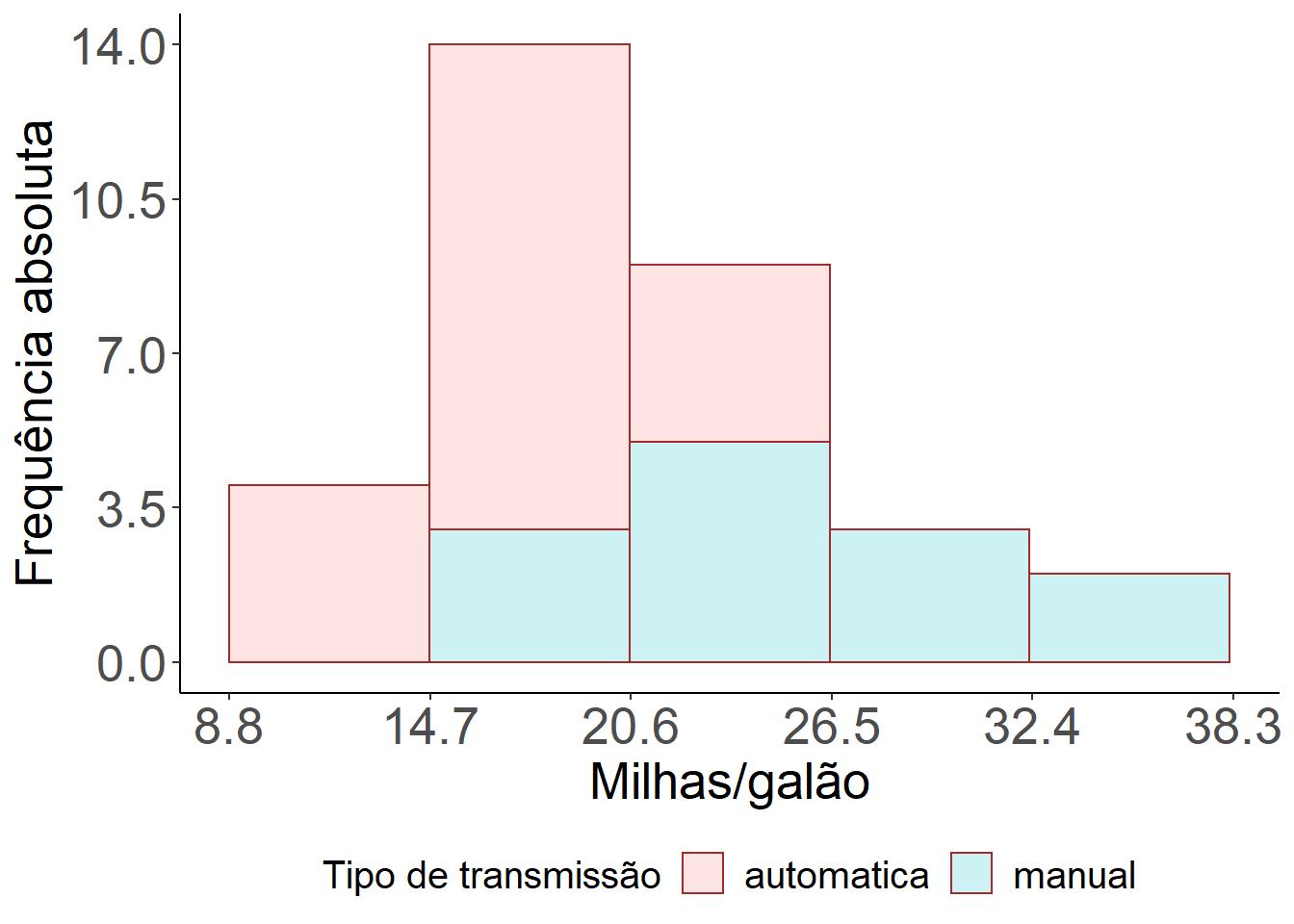
ggplot(mtcars) +
geom_histogram(aes(x = mpg, y = (..count..), fill=as.factor(am)), bins=5,
colour="brown", alpha=0.2)+
labs(x = "Milhas/galão", y = "Frequência absoluta", fill = "Tipo de transmissão") +
scale_y_continuous(breaks = c(seq(0,15,3.5))) +
scale_x_continuous(breaks = c(seq(8.8,38.3,5.9))) +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
Antes de construírmos o próximo histograma, precisamos apresentar a função facet do ggplot2. Esta função permite a construção de gráficos em facetas. O que é isso? Suponha que estamos interessados em construírmos um histograma baseado no anteriormente apresentado. Mas o nosso interesse maior é apresentar um histograma individual para cada tipo de transmissão am considerando a variável contínua mpg. Abaixo apresentamos a construção deste histograma.
cor <- gray(0:1 / 2)
ggplot(mtcars) +
geom_histogram(aes(x = mpg, y = (..count..)/sum(..count..)*100, fill=as.factor(am)),
bins=5, colour="brown", alpha=0.2)+
facet_wrap(~am)+
labs(x = "Milhas/galão", y = "Frequência percentual", fill = "Tipo de transmissão") +
scale_y_continuous(breaks = c(seq(0,60,10))) +
scale_x_continuous(breaks = c(seq(8.8,38.3,5.9))) +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=20),
legend.text=element_text(size=20), axis.text=element_text(size=12),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
strip.text.x = element_text(size=0),
strip.background = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
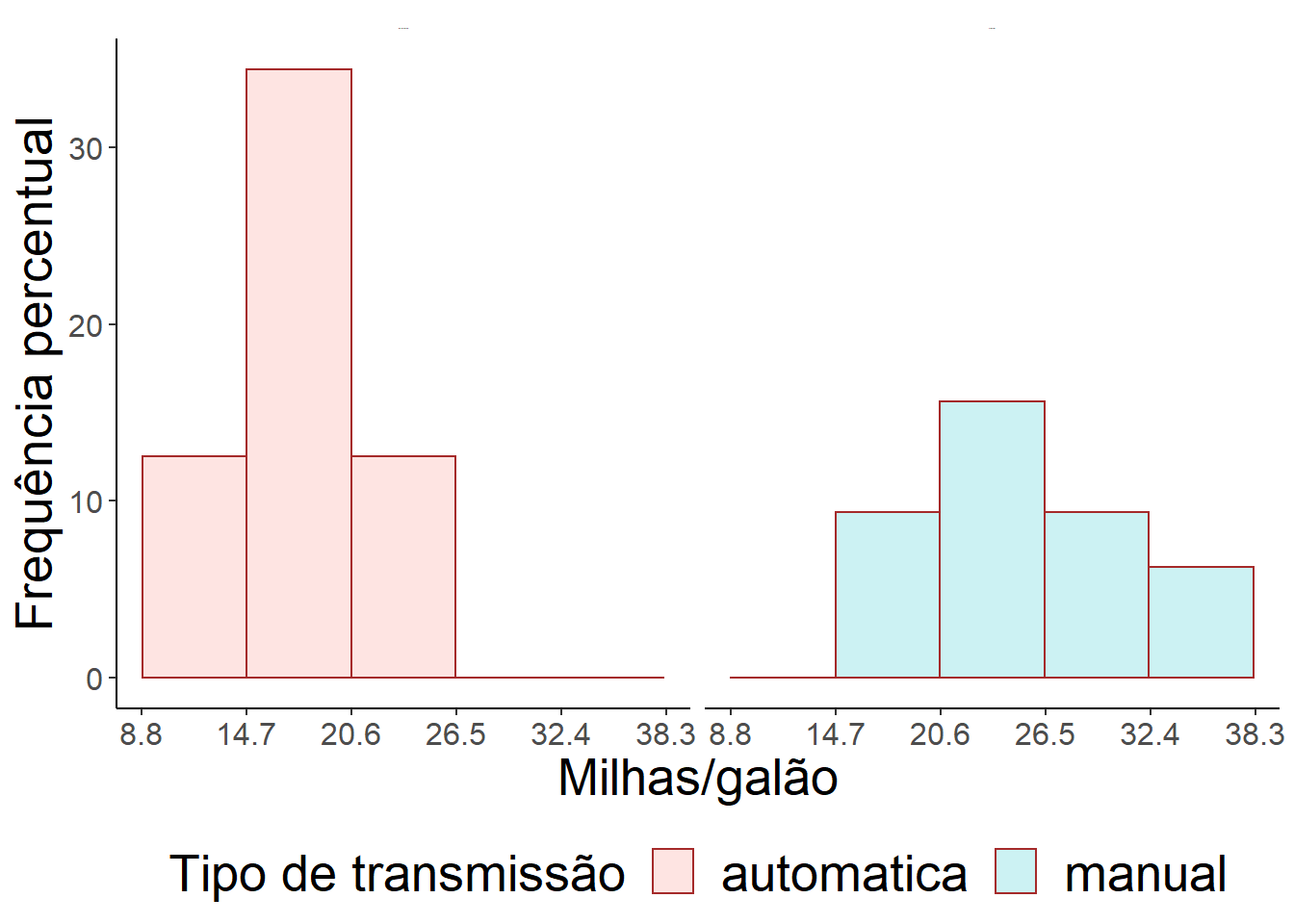
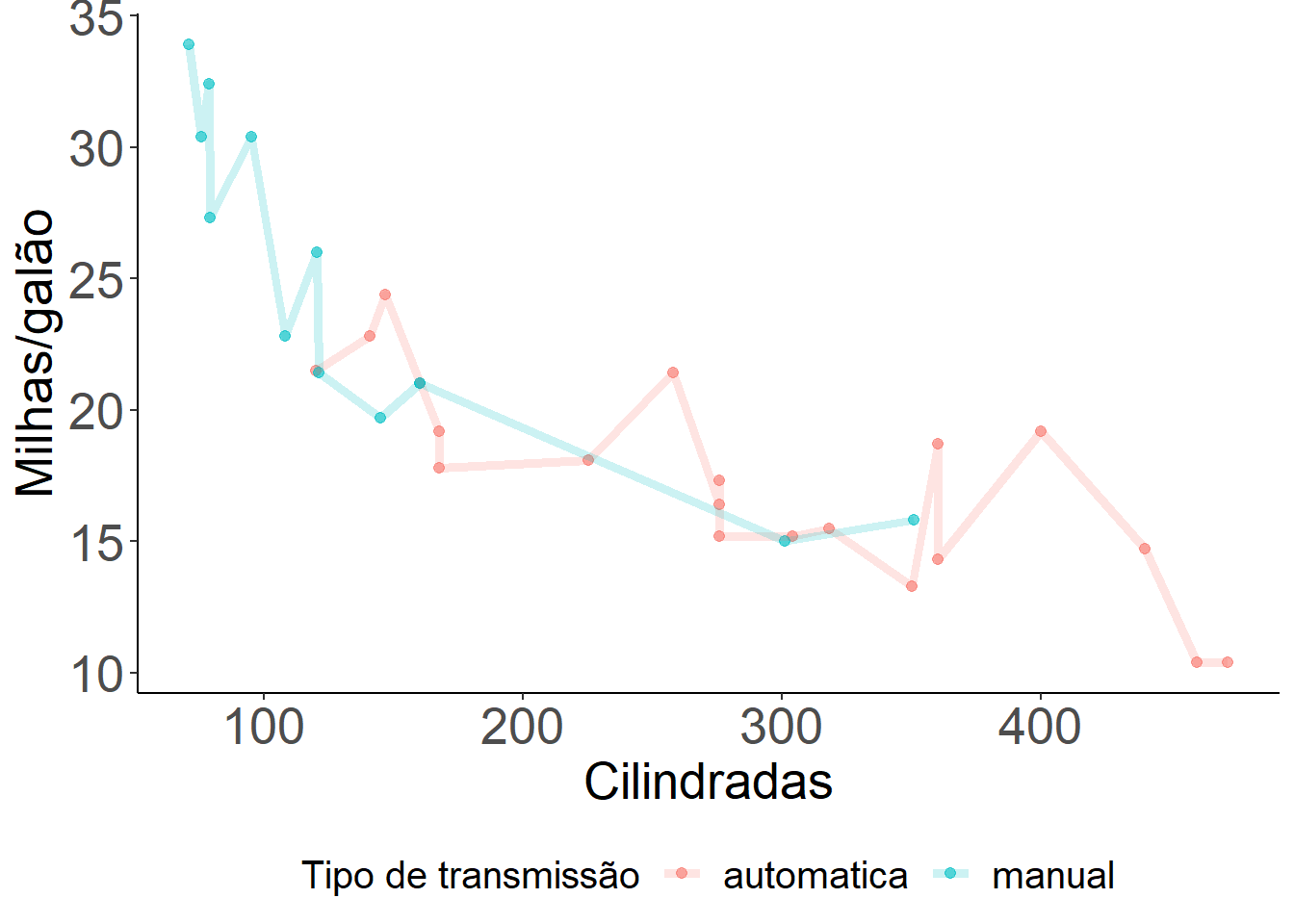
Vamos agora apresentar um exemplo de como construir um gráfico de tendência destacando-se os pontos de dispersão dos dados.
ggplot(mtcars, aes(x = disp, y = mpg)) +
geom_point(aes(colour=as.factor(am)), alpha=0.6, size=1.7)+
geom_line(aes(colour=as.factor(am)), alpha=0.2, size=1.7, linetype=1)+
labs(x = "Cilindradas", y = "Milhas/galão", colour = "Tipo de transmissão") +
theme_bw() +
theme(legend.position="bottom",
legend.box = "horizontal",legend.title=element_text(size=15),
legend.text=element_text(size=15), axis.text=element_text(size=20),
axis.title=element_text(size=20), axis.line = element_line(colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())
Como o usuário faria para construir estes histogramas e gráficos de tendência sem utilizar a classificação por níveis da variável am? A construção destes gráficos fica como exercício para o usuário.
Segunda parte
Construindo gráficos a partir de um conjunto de dados original usando os pacotes tydeverse, tibble e dplyr do R.
O que preciso saber do pacote dplyr:
| Funções | Resultados |
|---|---|
| filter() | seleciona observações das variáveis por seus valores assumidos |
| arrange() | reordena as linhas (observações) |
| select() | seleciona variáveis por seus nomes (rótulos) |
| mutate() | cria novas variáveis com funções de variáveis existentes |
| summarize() | reune muitos valores em um único resumo |
| group_by() | muda o escopo de cada função anterior em todo o conjunto de dados para operar grupo por grupo. |
Uma vez apresentado as funções do pacote dplyr, vamos agora apresentar os argumentos dessas funções. O primeiro argumento é um data frame. Os argumentos subsequentes descrevem o que fazer com o data frame usando os nomes das variáveis sem aspas.
O pacote covid19br foi criado por pesquisadores da UFMG e permite ao usuário a coleta, em tempo real, de algumas informações sobre a doença COVID-19 nas unidades de saúde do Brasil, apresentando informações como número de casos e mortes novos e acumulados, diariamente, no Brasil e no mundo. Ainda, essas informações estão separadas por estado, região, municípios, por semana epidemiológica, datas, entre outros.
Nós vamos aproveitar esse pacote para apresentarmos as funções do pacote dplyr e também construir gráficos com o pacote ggplot2.
data <- downloadCovid19("states")# dados por municípios brasileiros
## Downloading COVID-19 data from the official Brazilian repository: https://covid.saude.gov.br/
## Please, be patient...
## Done!
glimpse(data)
## Rows: 26,136
## Columns: 12
## $ region <chr> "North", "North", "North", "North", "North", "North", "No~
## $ state <chr> "RO", "RO", "RO", "RO", "RO", "RO", "RO", "RO", "RO", "RO~
## $ date <date> 2020-02-25, 2020-02-26, 2020-02-27, 2020-02-28, 2020-02-~
## $ epi_week <int> 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 11, 11, 11, 11~
## $ newCases <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ accumCases <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ newDeaths <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ accumDeaths <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ newRecovered <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N~
## $ newFollowup <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N~
## $ pop <dbl> 1777225, 1777225, 1777225, 1777225, 1777225, 1777225, 177~
## $ state_code <int> 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 1~
Não se preocupe com a estrutura apresentada nesse conjunto de dados. Trata-se de um tibble, um data frame com algumas particularidades. Note que essas estrutura de data frame traz algumas informações, como a dimensão dos dados, o tipo de variável que está em cada uma das colunas (categórica, inteiro, caractere, etc.), entre outras.
| Representação | Tipo de variável |
|---|---|
| int | números inteiros |
| dbl | doubles (números reais) |
| chr | vetores de caracteres (strings) |
| dttm | datas-tempos (uma data + um horário) |
| fctr | valores lógicos (TRUE ou FALSE) |
| date | datas |
Antes de apresentarmos as funções do pacote dplyr precisamos conhecer alguns caracteres lógicos e suas representações.
| Caractere lógico | Representação |
|---|---|
| == | igual |
| & | conectivo e (interseção) |
| | | conectivo ou (união) |
| > | maior do que |
| < | menor do que |
| >= | maior do que ou igual a |
| <= | menor do que ou igual a |
| != | diferente |
| %in% | concatenar |
As funções do pacote dplyr.
filter(data, date >= "2022-02-20" & state == "SP" & epi_week == 8)
## region state date epi_week newCases accumCases newDeaths
## 1: Southeast SP 2022-02-20 8 6424 4935771 26
## 2: Southeast SP 2022-02-21 8 2470 4938241 23
## 3: Southeast SP 2022-02-22 8 15999 4954240 310
## 4: Southeast SP 2022-02-23 8 15427 4969667 298
## 5: Southeast SP 2022-02-24 8 15228 4984895 303
## 6: Southeast SP 2022-02-25 8 14764 4999659 211
## 7: Southeast SP 2022-02-26 8 11290 5010949 211
## accumDeaths newRecovered newFollowup pop state_code
## 1: 163160 NA NA 45919049 35
## 2: 163183 NA NA 45919049 35
## 3: 163493 NA NA 45919049 35
## 4: 163791 NA NA 45919049 35
## 5: 164094 NA NA 45919049 35
## 6: 164305 NA NA 45919049 35
## 7: 164516 NA NA 45919049 35
arrange(data, state)
## region state date epi_week newCases accumCases newDeaths
## 1: North AC 2020-02-25 9 0 0 0
## 2: North AC 2020-02-26 9 0 0 0
## 3: North AC 2020-02-27 9 0 0 0
## 4: North AC 2020-02-28 9 0 0 0
## 5: North AC 2020-02-29 9 0 0 0
## ---
## 26132: North TO 2022-10-15 41 0 344594 0
## 26133: North TO 2022-10-16 42 0 344594 0
## 26134: North TO 2022-10-17 42 19 344613 0
## 26135: North TO 2022-10-18 42 0 344613 0
## 26136: North TO 2022-10-19 42 0 344613 0
## accumDeaths newRecovered newFollowup pop state_code
## 1: 0 NA NA 881935 12
## 2: 0 NA NA 881935 12
## 3: 0 NA NA 881935 12
## 4: 0 NA NA 881935 12
## 5: 0 NA NA 881935 12
## ---
## 26132: 4205 NA NA 1572866 17
## 26133: 4205 NA NA 1572866 17
## 26134: 4205 NA NA 1572866 17
## 26135: 4205 NA NA 1572866 17
## 26136: 4205 NA NA 1572866 17
select(data, region , date, state, newCases, accumCases)
## region date state newCases accumCases
## 1: North 2020-02-25 RO 0 0
## 2: North 2020-02-26 RO 0 0
## 3: North 2020-02-27 RO 0 0
## 4: North 2020-02-28 RO 0 0
## 5: North 2020-02-29 RO 0 0
## ---
## 26132: Midwest 2022-10-15 DF 0 839752
## 26133: Midwest 2022-10-16 DF 0 839752
## 26134: Midwest 2022-10-17 DF 0 839752
## 26135: Midwest 2022-10-18 DF 2235 841987
## 26136: Midwest 2022-10-19 DF 78 842065
mutate(data, rate_newcases = newCases/pop*100000)
## region state date epi_week newCases accumCases newDeaths
## 1: North RO 2020-02-25 9 0 0 0
## 2: North RO 2020-02-26 9 0 0 0
## 3: North RO 2020-02-27 9 0 0 0
## 4: North RO 2020-02-28 9 0 0 0
## 5: North RO 2020-02-29 9 0 0 0
## ---
## 26132: Midwest DF 2022-10-15 41 0 839752 0
## 26133: Midwest DF 2022-10-16 42 0 839752 0
## 26134: Midwest DF 2022-10-17 42 0 839752 0
## 26135: Midwest DF 2022-10-18 42 2235 841987 0
## 26136: Midwest DF 2022-10-19 42 78 842065 0
## accumDeaths newRecovered newFollowup pop state_code rate_newcases
## 1: 0 NA NA 1777225 11 0.000000
## 2: 0 NA NA 1777225 11 0.000000
## 3: 0 NA NA 1777225 11 0.000000
## 4: 0 NA NA 1777225 11 0.000000
## 5: 0 NA NA 1777225 11 0.000000
## ---
## 26132: 11831 NA NA 3015268 53 0.000000
## 26133: 11831 NA NA 3015268 53 0.000000
## 26134: 11831 NA NA 3015268 53 0.000000
## 26135: 11831 NA NA 3015268 53 74.122765
## 26136: 11831 NA NA 3015268 53 2.586835
summarize(data, mean_newdeaths=mean(newDeaths), desv_pad= sd(newDeaths),
standard_error=desv_pad/sqrt(length(data)))
## mean_newdeaths desv_pad standard_error
## 1 26.30177 66.46069 19.18555
group_by(data, region, epi_week)
## # A tibble: 26,136 x 12
## # Groups: region, epi_week [265]
## region state date epi_week newCases accumCases newDea~1 accum~2 newRe~3
## <chr> <chr> <date> <int> <int> <int> <int> <int> <int>
## 1 North RO 2020-02-25 9 0 0 0 0 NA
## 2 North RO 2020-02-26 9 0 0 0 0 NA
## 3 North RO 2020-02-27 9 0 0 0 0 NA
## 4 North RO 2020-02-28 9 0 0 0 0 NA
## 5 North RO 2020-02-29 9 0 0 0 0 NA
## 6 North RO 2020-03-01 10 0 0 0 0 NA
## 7 North RO 2020-03-02 10 0 0 0 0 NA
## 8 North RO 2020-03-03 10 0 0 0 0 NA
## 9 North RO 2020-03-04 10 0 0 0 0 NA
## 10 North RO 2020-03-05 10 0 0 0 0 NA
## # ... with 26,126 more rows, 3 more variables: newFollowup <int>, pop <dbl>,
## # state_code <int>, and abbreviated variable names 1: newDeaths,
## # 2: accumDeaths, 3: newRecovered
Esse pacote é muito útil quando desejamos realizar uma análise exploratória de nossos dados. Vamos então construir alguns gráficos utilizando os recursos desse pacote e também do ggplot2.
Suponha que estamos interessados em conhecer, “a priori”, quantas mortes por COVID-19 ocorreram em cada uma das unidades federativas brasileiras, no dia 20-02-2022. Como proceder?
Dados <- select(data, epi_week , state, newDeaths, date)
resultados <- filter(Dados, epi_week == 8 & date == "2022-02-20")
ggplot(resultados)+
geom_col(aes(x=as.factor(state), y=newDeaths, fill=as.factor(state)),
alpha=0.65, position = "stack")+
labs(x = "Unidades da federação", y = "Novas mortes - semana 30")+
theme_bw()+
theme(legend.position="none",
legend.box = "vertical",legend.title=element_text(size=8),
legend.text=element_text(size=8), axis.text=element_text(size=8),
axis.title=element_text(size=8), axis.line = element_line(colour = "black"),
strip.text.x = element_text(size=0),
strip.background = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())+
scale_fill_discrete(name="UF")
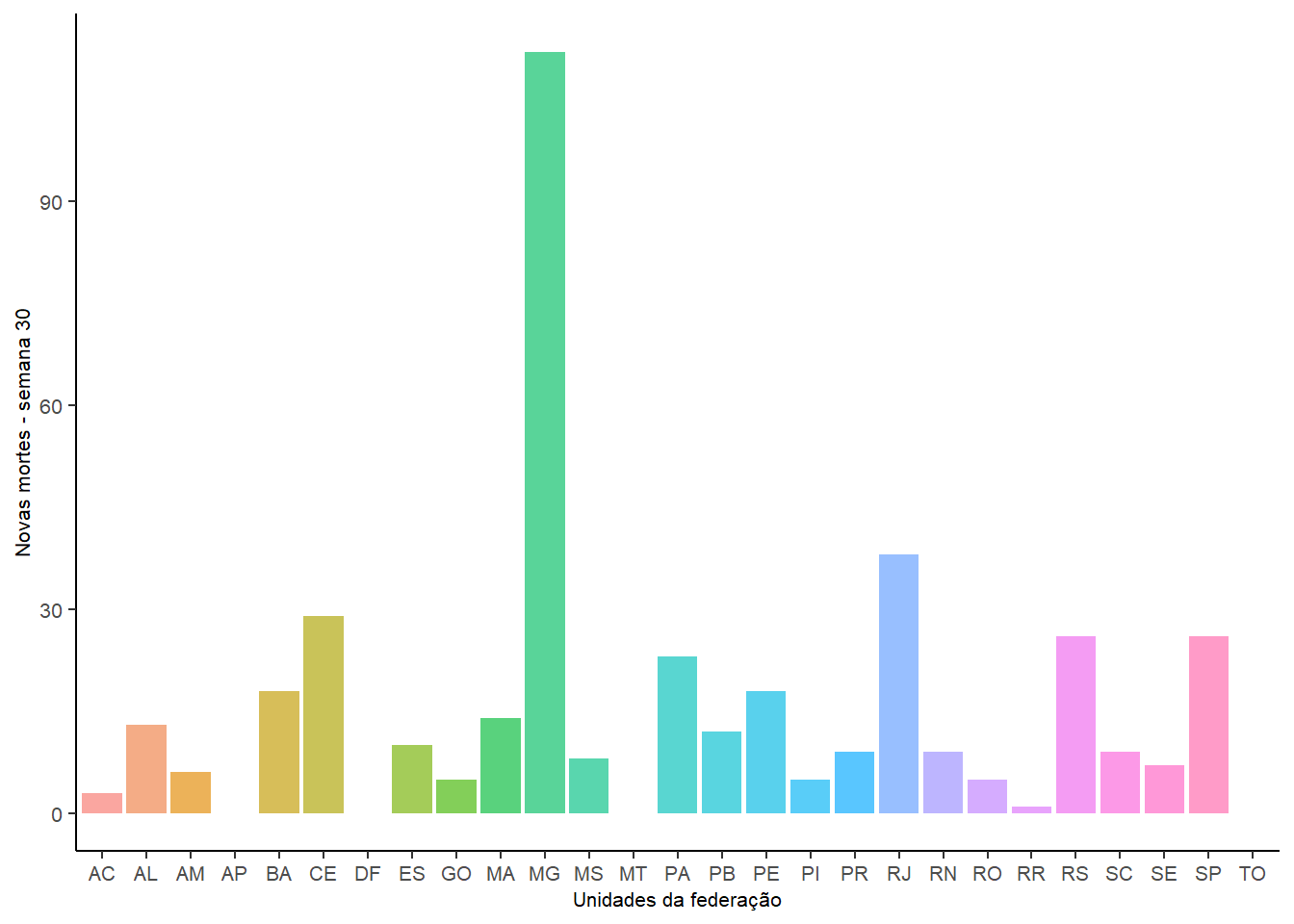
Um fato curioso deve ser notado: quando manipulamos o conto de dados data com as funções select e filter, nós atribuímos a cada tibble gerado por essas funções um rótulo. Agora, imagine que, dentro do mesmo conjunto de dados, nós precisamos utilizar todas as seis funções do pacote dplyr. Seria inviável proceder como da forma anterior. Para corrigir esse problema, foi criado o pacote magrittr onde foi criado o operador pipe %>%. Essa ferramenta é utilizada para expressar claramente uma sequência de múltiplas operações. Este pacote já é carregado automaticamente com o dplyr.
Em nosso próximo exemplo, suponha que deseja-se conhecer a evolução diária das novas mortes considerando o tempo de infecção por COVID-19 da semana 1 até a semana 8 de 2021 e 2022, para as unidades federativas da região sudeste. Entretanto, para efeitos de comparação, as populações de cada uma das UF’s se difere, o que torna a comparação entre elas inviável. Esse é o motivo pelo qual calculamos algumas medidas auxiliares quando há heterogeneidade populacional. Uma dessas medidas é denominada de taxa e seu cálculo é oriundo da razão entre o número de casos favoráveis e o total de indivíduos da população de cada uma das áreas estudas, multiplicado por alguma constante de padronização. Nós vamos respeitar as regras utilizadas pelo Instituto Brasileiro de Geografia e Estatística (IBGE) e considerar essa constante igual a 100,000. Desse modo:
cor <- heat.colors(4, rev = TRUE)
resultados <- data %>%
mutate(year = as.numeric(format(date, "%Y")),
rate = newDeaths/pop*100000)%>%
select(newDeaths, epi_week, state, year, rate)%>%
filter(epi_week>= 1 & epi_week <= 8 & state %in% c("SP", "RJ", "MG", "ES") & year %in% c(2021, 2022))
ggplot(resultados, aes(x=as.factor(epi_week), y = rate, fill=as.factor(state)))+
facet_wrap(~year)+
geom_bar(stat="identity", position = "dodge", alpha=0.45) +
labs(x = "Semana de infecção", y = "Novas mortes - Sudeste") +
theme_bw()+
theme(legend.position="right",
legend.box = "vertical",legend.title=element_text(size=8),
legend.text=element_text(size=8), axis.text=element_text(size=8),
axis.title=element_text(size=8), axis.line = element_line(colour = "black"),
strip.text.x = element_text(size=0),
strip.background = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
panel.background = element_blank())+
scale_fill_manual(name="UF", values = cor)
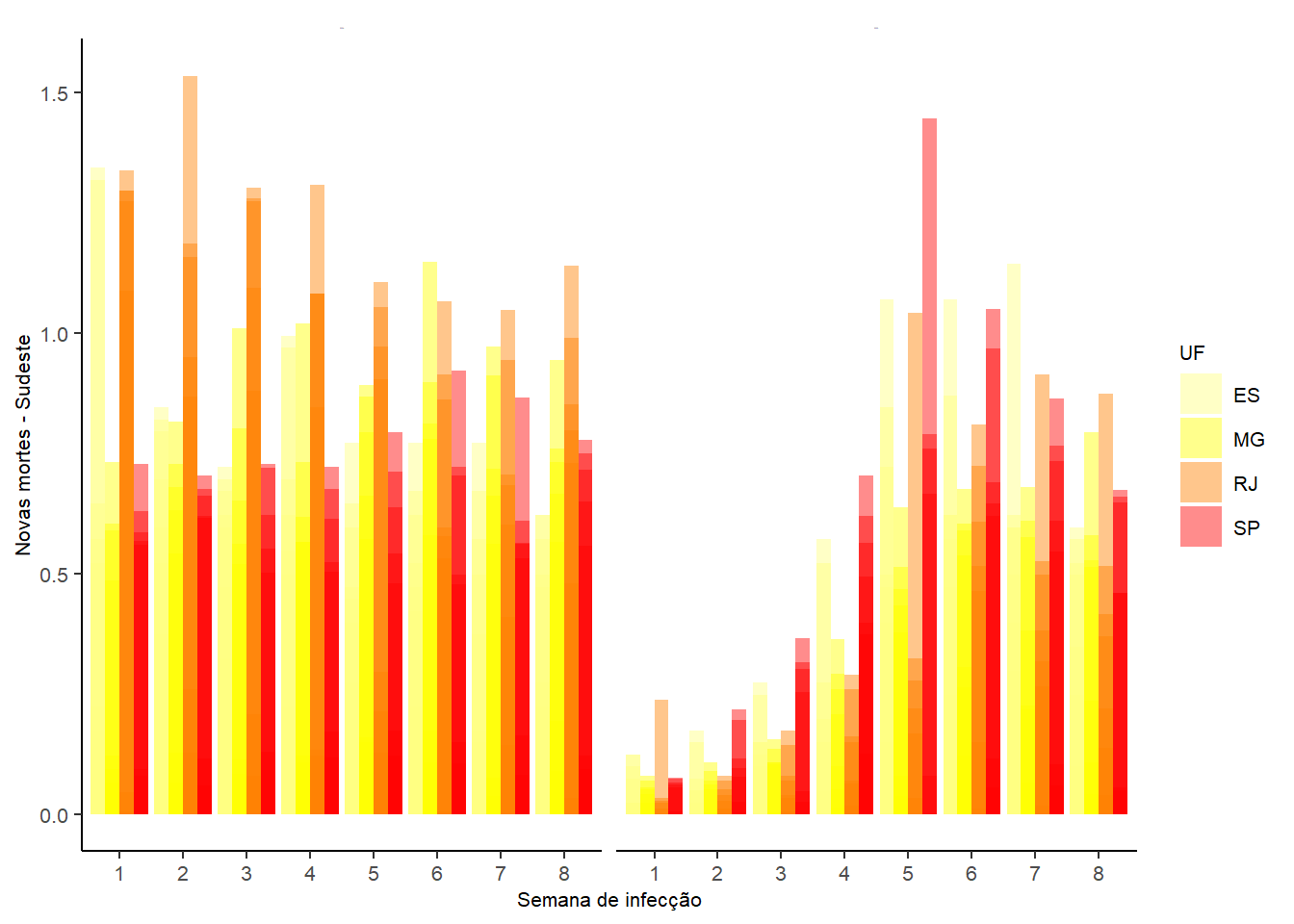
Nós também podemos produzir mapas utilizando o pacote ggplot2. Entretanto, nós precisamos de algum arquivo que contenha as coordenadas do mapa desejado em forma de polígonos ou até mesmo imagens (raster). Para tal, nós vamos utilizar o pacote geobr, que foi criado pelo Instituto de Pesquisa Econômica Aplicada - Ipea. Vejamos:
uf <- data %>%
select(state, newDeaths, newCases, accumDeaths, accumCases,
pop, date)%>%
filter(date == "2022-02-23")%>%
mutate(ratenewcases = newCases/pop*100000,
rateaccumcases = accumCases/pop*100000,
ratenewdeaths = newDeaths/pop*100000,
rateaccumdeaths = accumDeaths/pop*100000)
library(geobr)
dados_mapa <- read_state(year=2019, showProgress = FALSE)
## Using year 2019
colnames(dados_mapa)[2] <- "state"
dados_final <- left_join(dados_mapa, uf, "state")
glimpse(dados_final)
## Rows: 27
## Columns: 16
## $ code_state <dbl> 11, 12, 13, 14, 15, 16, 17, 21, 22, 23, 24, 25, 26, 27~
## $ state <chr> "RO", "AC", "AM", "RR", "PA", "AP", "TO", "MA", "PI", ~
## $ name_state <chr> "Rondônia", "Acre", "Amazônas", "Roraima", "Pará", "Am~
## $ code_region <dbl> 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, ~
## $ name_region <chr> "Norte", "Norte", "Norte", "Norte", "Norte", "Norte", ~
## $ newDeaths <int> 16, 4, 3, 1, 17, 2, 2, 14, 5, 57, 7, 9, 15, 12, 4, 26,~
## $ newCases <int> 2741, 654, 575, 361, 2476, 52, 723, 1283, 645, 1907, 1~
## $ accumDeaths <int> 7036, 1966, 14101, 2126, 17716, 2100, 4095, 10739, 761~
## $ accumCases <int> 366864, 119090, 571174, 152146, 709489, 160025, 296677~
## $ pop <dbl> 1777225, 881935, 4144597, 605761, 8602865, 845731, 157~
## $ date <date> 2022-02-23, 2022-02-23, 2022-02-23, 2022-02-23, 2022-~
## $ ratenewcases <dbl> 154.229206, 74.155125, 13.873484, 59.594461, 28.781110~
## $ rateaccumcases <dbl> 20642.519, 13503.263, 13781.171, 25116.506, 8247.125, ~
## $ ratenewdeaths <dbl> 0.90027993, 0.45354816, 0.07238339, 0.16508161, 0.1976~
## $ rateaccumdeaths <dbl> 395.8981, 222.9189, 340.2261, 350.9635, 205.9314, 248.~
## $ geom <MULTIPOLYGON [°]> MULTIPOLYGON (((-65.3815 -1..., MULTIPOLY~
#plotar os mapas
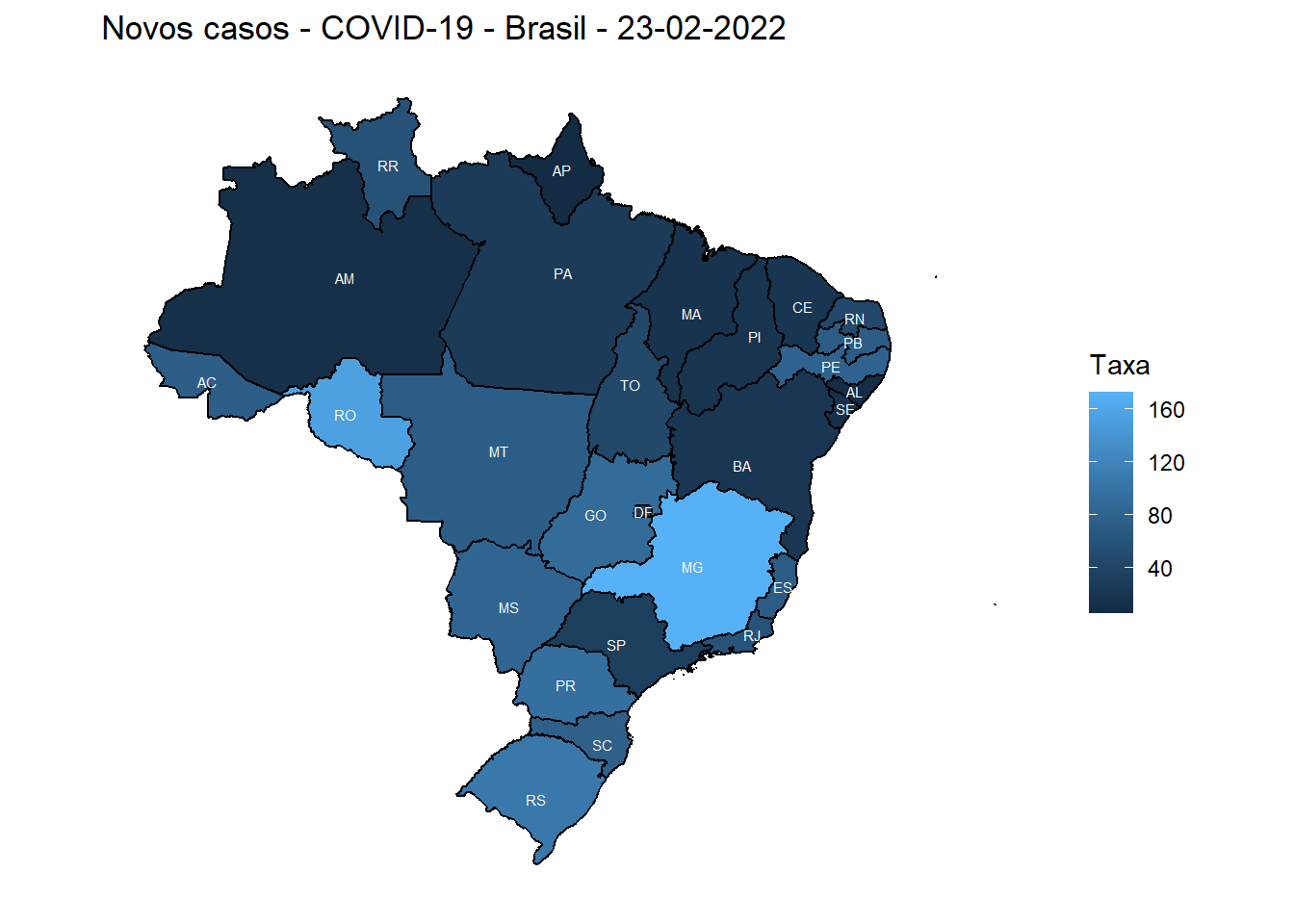
dados_final %>%
ggplot() +
geom_sf(aes(fill = ratenewcases), color = "black") +
geom_sf_text(aes(label = state), size = 2, color = "white")+
labs(title = "Novos casos - COVID-19 - Brasil - 23-02-2022", fill = "Taxa") +
theme_minimal()+
theme(axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())
## Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
## give correct results for longitude/latitude data
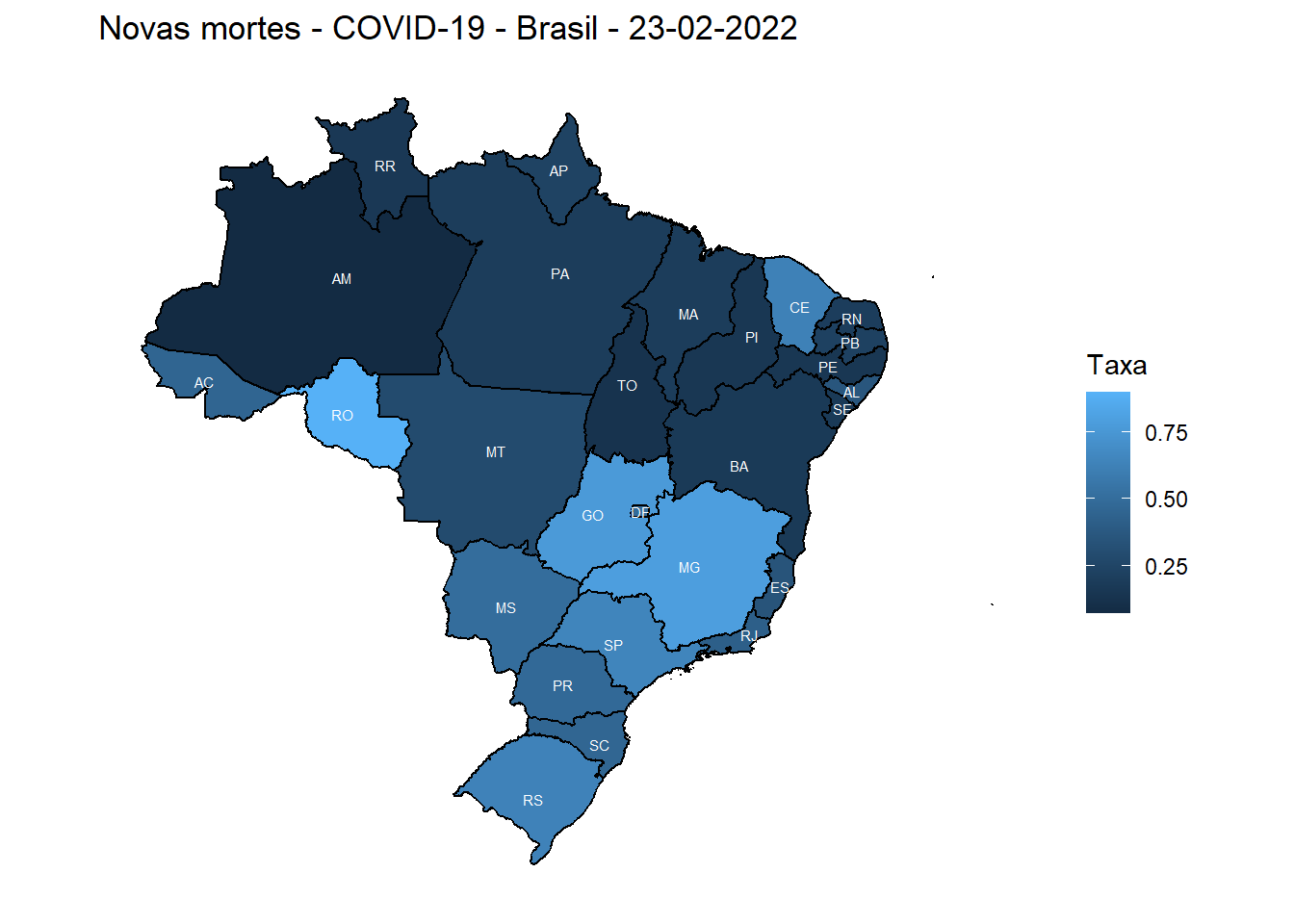
dados_final %>%
ggplot() +
geom_sf(aes(fill = ratenewdeaths), color = "black") +
geom_sf_text(aes(label = state), size = 2, color = "white")+
labs(title = "Novas mortes - COVID-19 - Brasil - 23-02-2022", fill = "Taxa") +
theme_minimal()+
theme(axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())
## Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
## give correct results for longitude/latitude data
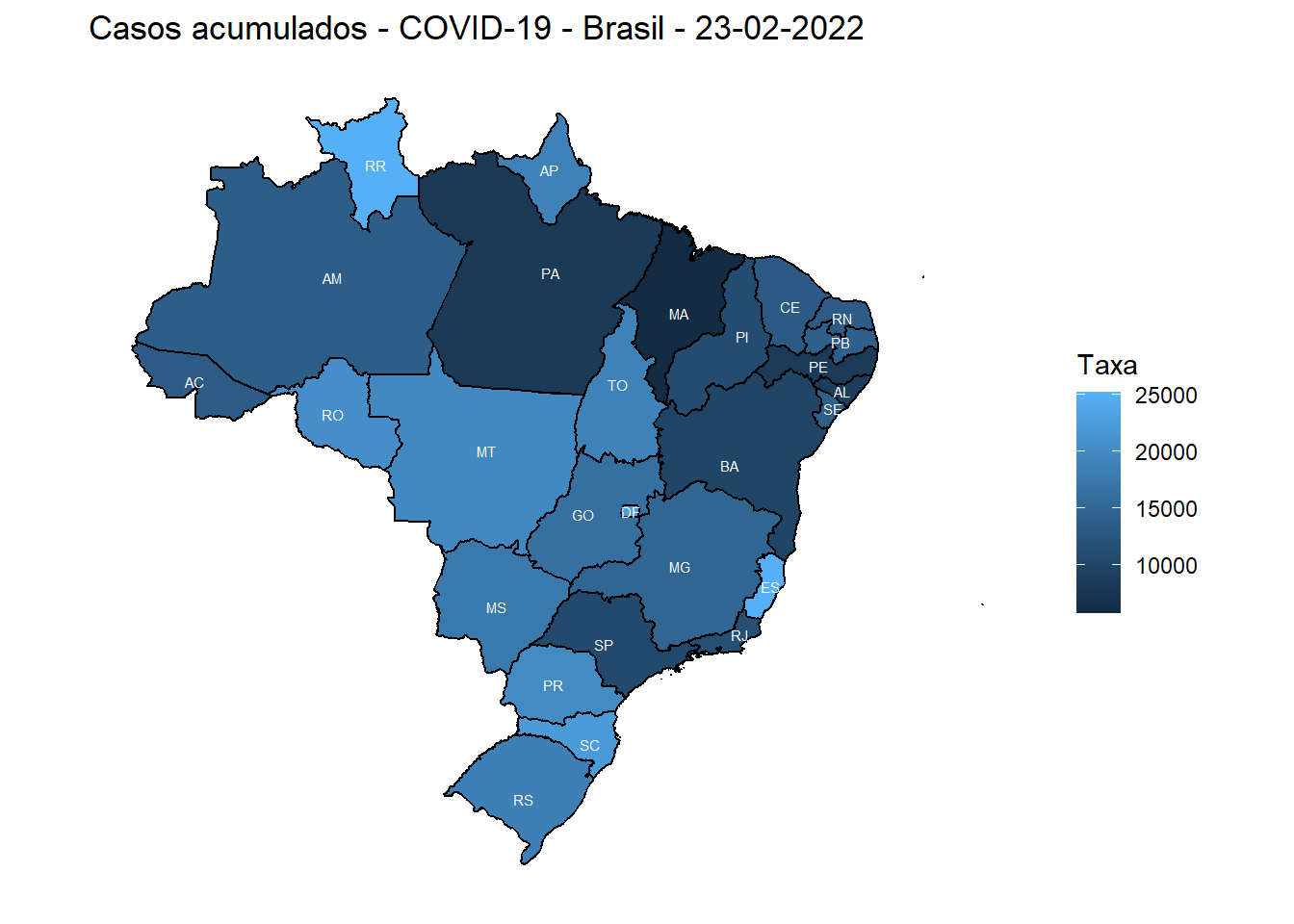
dados_final %>%
ggplot() +
geom_sf(aes(fill = rateaccumcases), color = "black") +
geom_sf_text(aes(label = state), size = 2, color = "white")+
labs(title = "Casos acumulados - COVID-19 - Brasil - 23-02-2022", fill = "Taxa") +
theme_minimal()+
theme(axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())
## Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
## give correct results for longitude/latitude data
dados_final %>%
ggplot() +
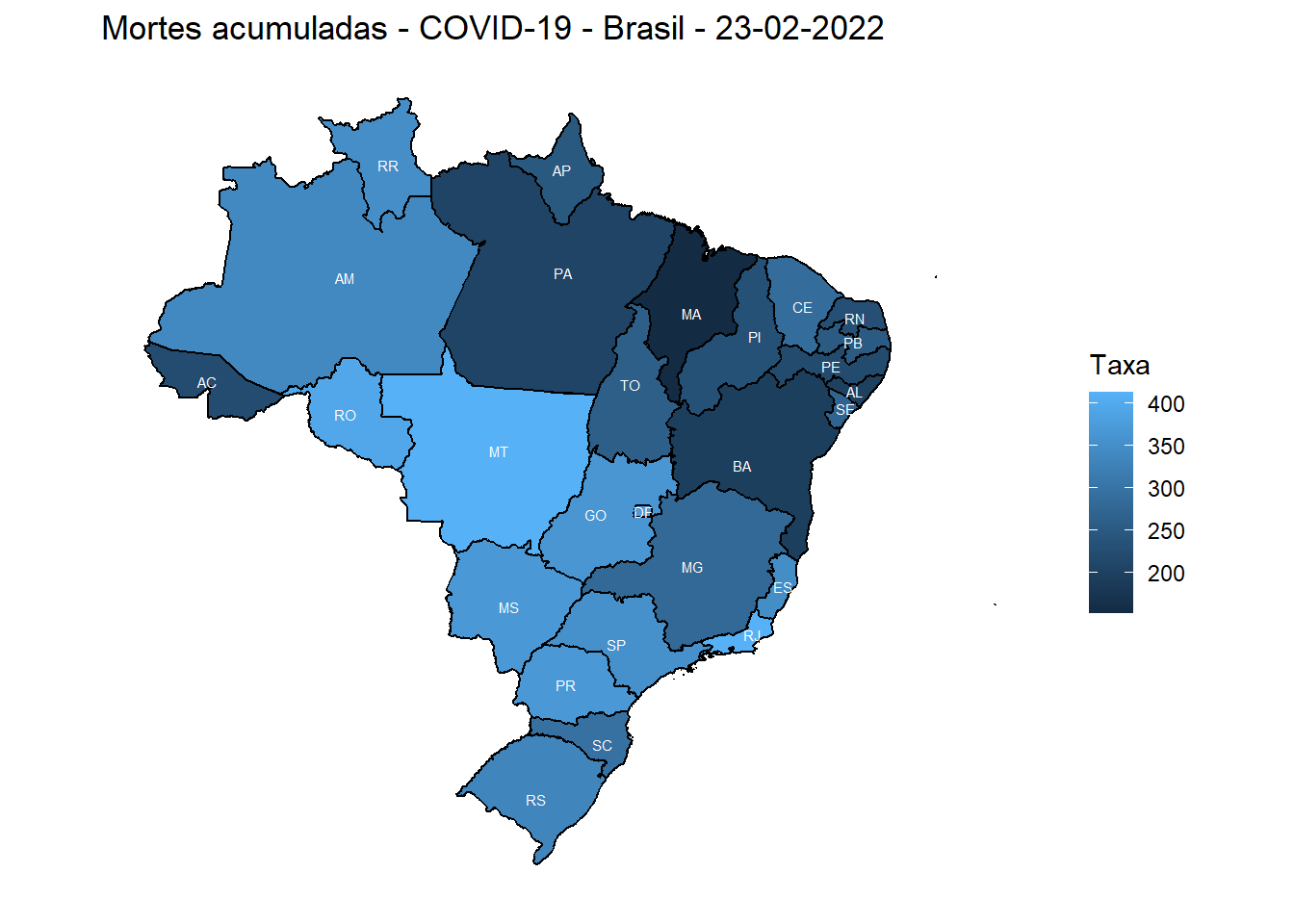
geom_sf(aes(fill = rateaccumdeaths), color = "black") +
geom_sf_text(aes(label = state), size = 2, color = "white")+
labs(title = "Mortes acumuladas - COVID-19 - Brasil - 23-02-2022", fill = "Taxa") +
theme_minimal()+
theme(axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())
## Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
## give correct results for longitude/latitude data